7 数据库物理存储和索引
7.1 数据库的物理存储
7.1.1 计算机系统的存储架构
内存的层级结构
见体系结构,微机原理
磁盘
最小读写单位:扇区
磁盘块/页:连续的多个扇区
一个页面的访问时间包括:寻道,旋转,传输
顺序访问对磁盘更加友好,平均的访问时间更少
缓冲池:内存中存放大量磁盘页面的区域,减少磁盘的访问
缓冲池页面替换策略
LRU,最近最少使用,least recent use
在某些情况下使用不佳,见体系结构
先进先出
MRU,most recent use,在连接操作时使用
7.1.2 记录的组织方式
记录:字节的序列
有一个header用于描述记录(meta data),类似于Cache的tag
按照关系定义的顺序存储各个属性,定长的属性写在前边,变长的(VAR)用指针指向末尾,从后向前写;记录头后紧跟着指针数组,指向每个属性
每个属性值在记录中存储位置的偏移量是4B/8B的整数倍
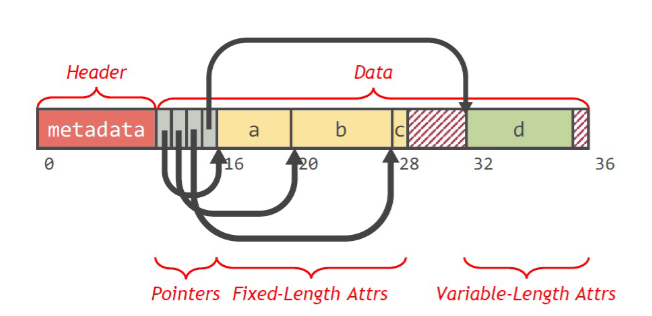
页布局:包含页头和页数据
页头就是meta data,页数据就是data
7.1.3 文件的组织方式
无序文件组织:记录可以在磁盘上的任意位置存储
存在两种管理方式:
- 删除的文件做标记,不删除;新文件加在末尾
- 删除的文件做标记;新文件插入在标记处
文件需要定期重组,真的删除标记了删除的文件,将文件之间连续排列,回收未利用空间
特点:插入效率高,检索效率非常低
有序文件组织:记录按照某个属性顺序插入
插入效率低,检索效率高
溢出文件:为未来可能的文件预留一块空间,用来插入文件,这些文件称为溢出文件
溢出文件和主文件各自是有序的,但二者是独立的
必要时需要重组
散列文件:就是哈希表储存文件,需要一个散列函数用于确定地址分布
插入效率高,检索效率高
7.2 数据库索引
7.2.1 索引分类
按物理存储类型
- 聚集索引:数据按照查找键排序,一张表只能有一个
- 非聚集索引:不按键排列,可以有多个
按粒度
- 稀疏索引:索引到文件
- 稠密索引:索引到记录
等
查询类型
- 点查询:xx=0,使用哈希索引,B+树索引
- 范围查询:xx>0,使用B+树索引
- 多列条件查询:xx=0 AND yy=1,位图索引
- 空间范围查询:多维的范围查询,多维索引
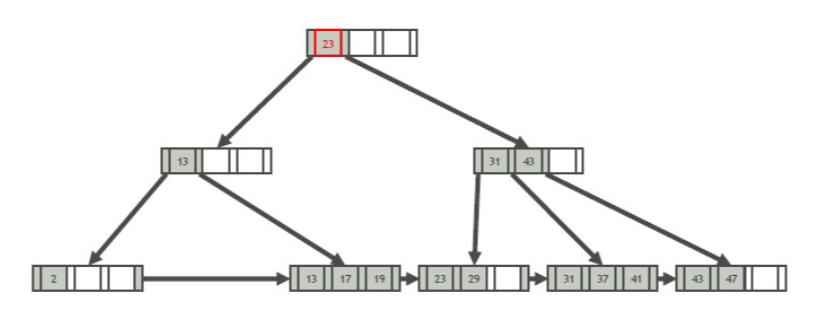
7.2.2 B+树索引
结构:平衡多叉查找树
扇出m:每个节点的最大分叉数
- 子节点数目范围:\([\lceil \frac{m}{2} \rceil, m]\)
- 查找键数目范围:\([\lceil \frac{m}{2} \rceil-1, m-1]\),分为了N+1个子节点
叶节点之间存在双向链表
节点的左子树都比节点小,右子树都大;叶节点是升序的
访问的时间是\(\log n\),仅与树的高度有关

点查询:从根节点逐层加载,直到叶节点,一定会到叶节点
区间查询:查询\([L,H]\)的值,根据\(L\)找左端点,然后用链表一直找,直到\(>H\),\(\leq H\)的都输出
插入算法
- 找到叶节点L
- 有空间就插入
- 没空间就分裂,向上递归
- 假设L的中间值为K,那么<K的放原来节点;>K的,将K作为父节点的一个关键字,插入到这个关键字的右子树
- 如果父节点也满了,需要继续分裂
- 向上递归,直到ROOT分裂,那么会多一个ROOT,B+树深一层
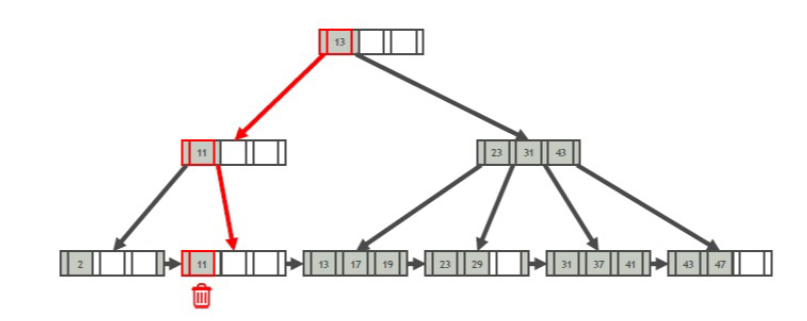
删除算法
- 找到叶节点L
- 删除了满足子树条件就ok
- 不满足,那么需要合并节点,向上递归
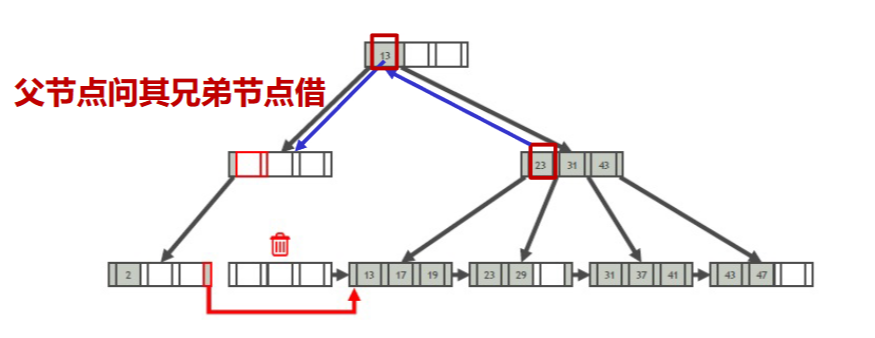
- 向兄弟节点借一个叶子,并且更新被借的兄弟节点,使二者都半满
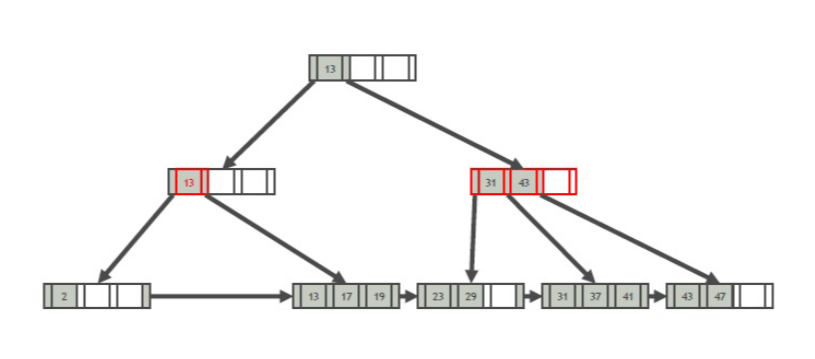
- 如果都不能半满,就合并两个父节点,将父节点的父节点变为子节点,子节点中值变为父节点
- 向上递归,直到ROOT合并,B+树少一层
7.2.3 哈希索引
静态哈希:桶的数目不变,发生溢出时需要添加桶并重排
- 闭哈希:寻找空位置:线性探测(+1,+2,+3,容易堆积),平方探测(+1,+4,+9)
- 开哈希:哈希桶链表,同一个地址,用链表连接,长了就没有查询效率了
动态哈希:桶的数目动态变化
- 可扩展哈希表:存在问题
- 每次扩容时会阻塞访问,降低性能
- 少量的桶多次溢出,却要对整个表扩容,造成空间浪费
- 线性哈希表:对可扩展哈希的解决