5 并发控制
5.1 并发事务的冲突
5.1.1 脏读
事务之间可以看到未提交的数据
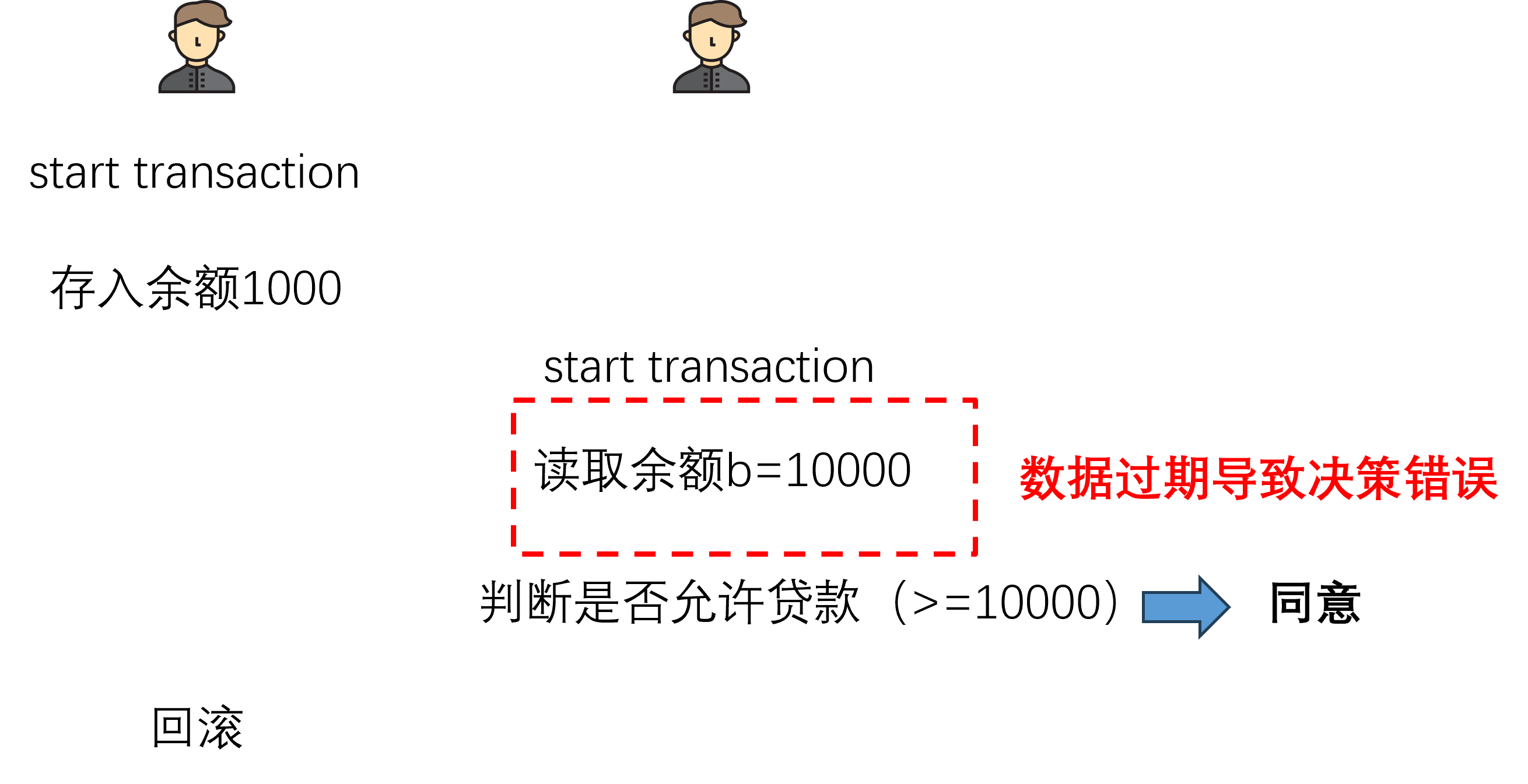
5.1.2 不可重复读
事务之间可以看到已提交的数据,但是不能得知数据是否会更新
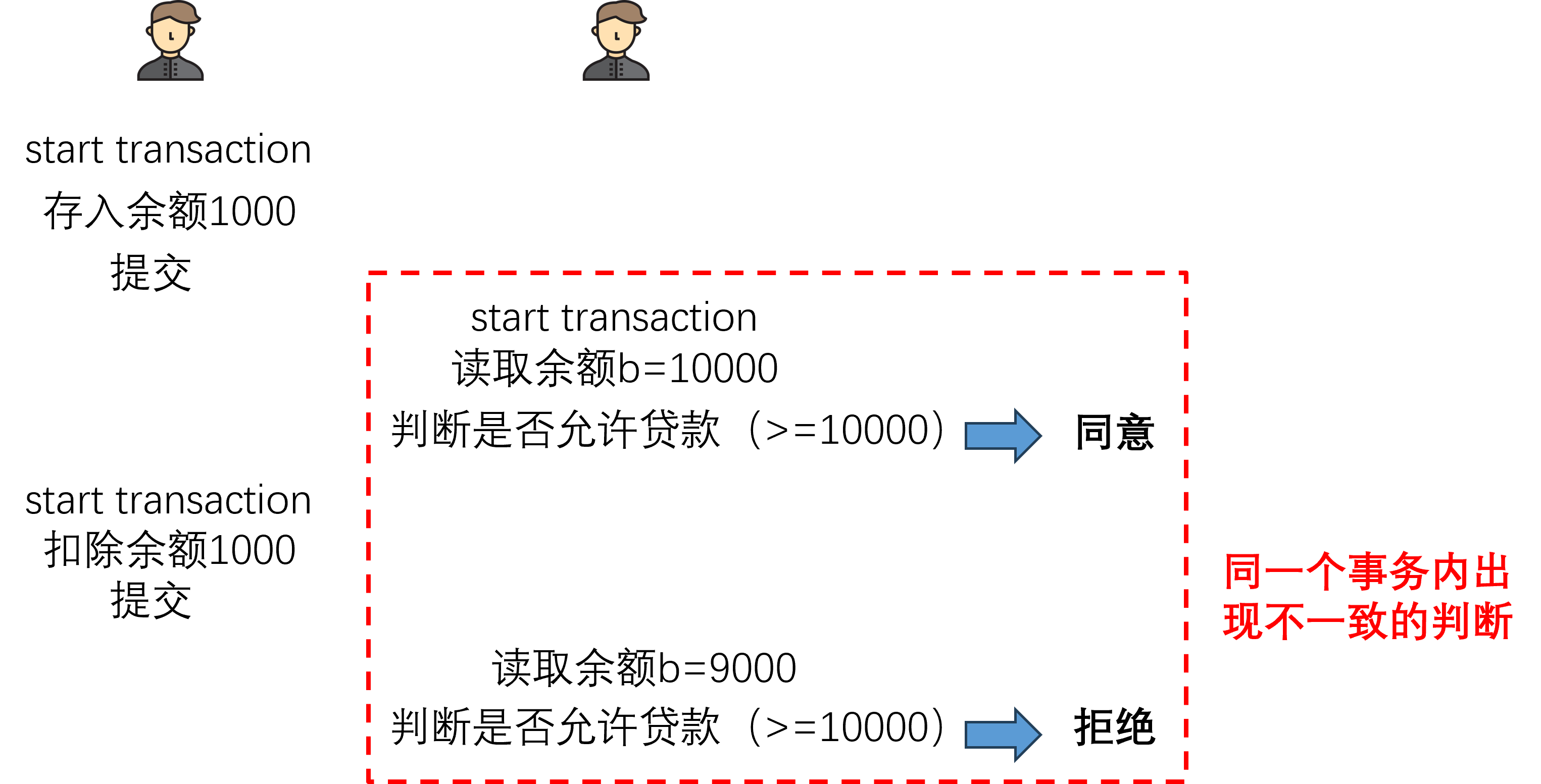
5.1.3 幻读
事务之间可以看到已提交的数据,但是不能得知数据的条目是否变化
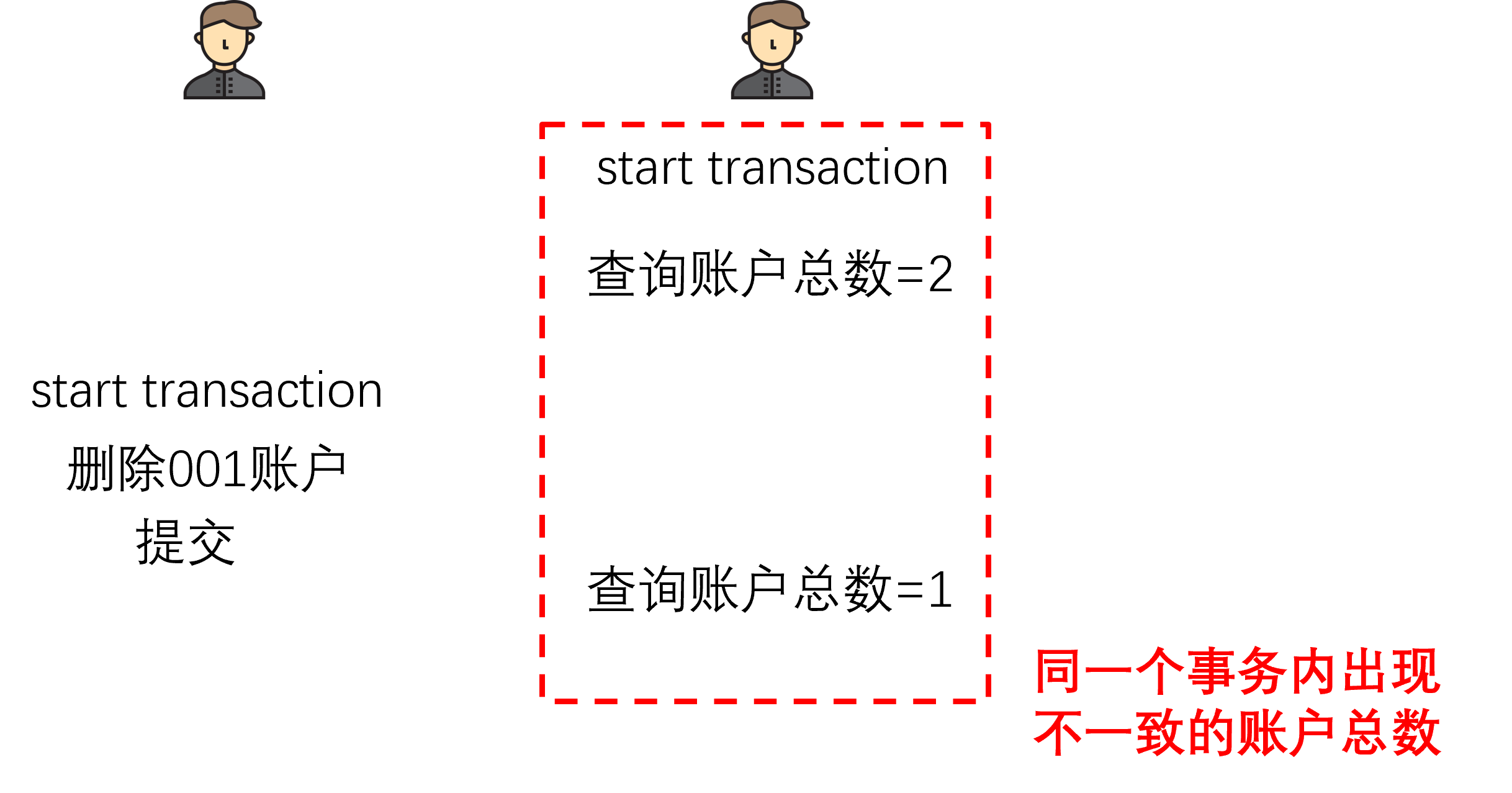
幻读和不可重复读的区别,大致可以对应为INSERT/DELETE和UPDATE的区别
5.1.4 写冲突
两个事务同时提交对一个数据的修改

5.1.5 隔离机制
- 读未提交:最低级的隔离,可以允许脏读
- 读提交:事务只能读取其他事务已提交的事务
- 可重复读:确保事务可以多次读取统一数据,保证每次结果相同
- 串行化:以串行的方式执行,没有并发,性能差
这几个隔离中,只有最高级的串行化可以避免写冲突

5.2 锁
并发错误来自于多个事务对一项数据的同时读写,因此出现了事务锁。锁一定是事务对数据项施加的。
5.2.1 共享锁(读锁,S锁)
某个事务在数据项d上加了S锁,那么
该事务只能读取d,不能修改
其他事务存在
- 不加锁的情况下无法读取d
- 加S锁可以读取d
5.2.2 互斥锁(写锁,X锁)
某个事务在d上加了X锁,那么
- 该事务能读写d
- 其他事务存在
- 不能对d加S/X锁
- 不加锁时无法读写d
5.2.3 锁带来的问题
在一个事务加锁的情况下,另一个事务无法操作数据,必须等待加锁事务结束,那么这可能导致
饿死:锁导致等待,等的时间可以很长
如何避免:先来先服务,按顺序给资源
不可解决不可重复读,幻读和写冲突
死锁:n个事务需要的锁和这个锁所在的事务成环
必须对事务的调度顺序做出规定
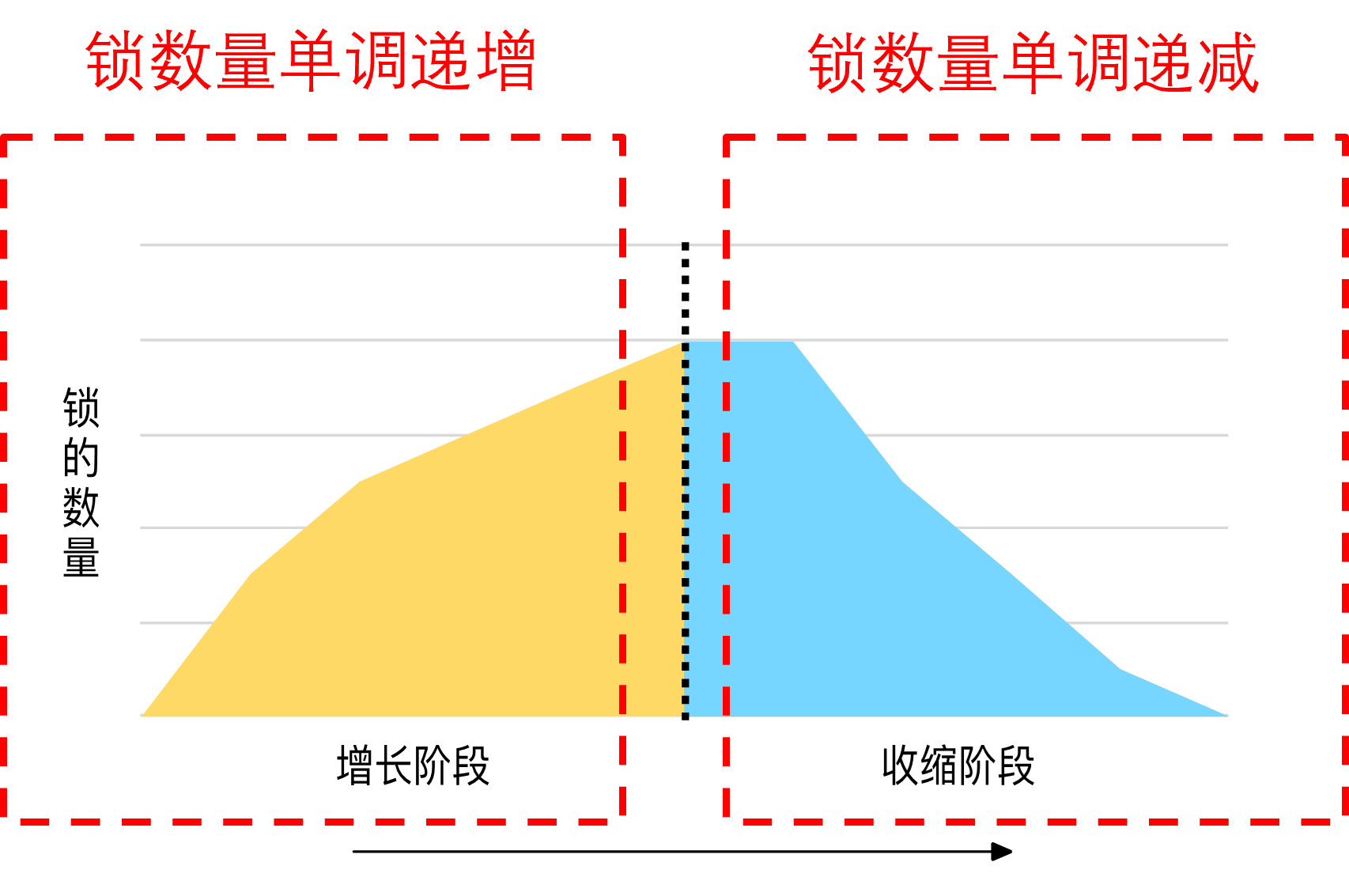
5.2.4 二阶段锁
希望事务将自己的操作一次性做完,且中途不能被打扰,这样就能解决所有的冲突,由此引入二阶段锁
将事务锁分为两个阶段
加锁阶段
- 在这个阶段事务可以获取所有需要的锁
- 每当事务访问一个新的数据时,必须先加锁
- 这个阶段持续到事务获取所有的锁
解锁阶段
- 一旦事务开始解锁,那就不能再加锁
- 开始于事务释放第一个锁,结束于释放了所有的锁
二阶段的锁数目变化如图
5.2.5 解决死锁
死锁预防
死锁的形成是因为两个事务相互等待,那么首先不能允许相互等待
有两种方式,但都是基于时间戳确定老事务To和新事物Tn
Wait-Die
如果Tn持有锁,To申请这个锁,那么To等待
如果To持有锁,Tn申请这个锁,那么Tn被撤销,但Tn保留创建的时间戳(否则会饿死)
Wound-Wait
如果Tn持有锁,To申请这个锁,那么Tn被撤销,保留原来的时间戳
如果To持有锁,Tn申请这个锁,那么Tn等待
死锁检测与恢复
检测:检测事务依赖,如果成环那么就产生了死锁,这时需要选择一个事务牺牲
牺牲的依据:
- 事务的时间戳
- 事务已经执行的语句数量
- 事务已经持有的锁
时间戳越新,执行的语句和持有的锁越少,那么事务越先被牺牲
设锁超时重启
设置一个事务的最长等待时间,当事务超时时仍没有取得需要的锁,那么事务重启
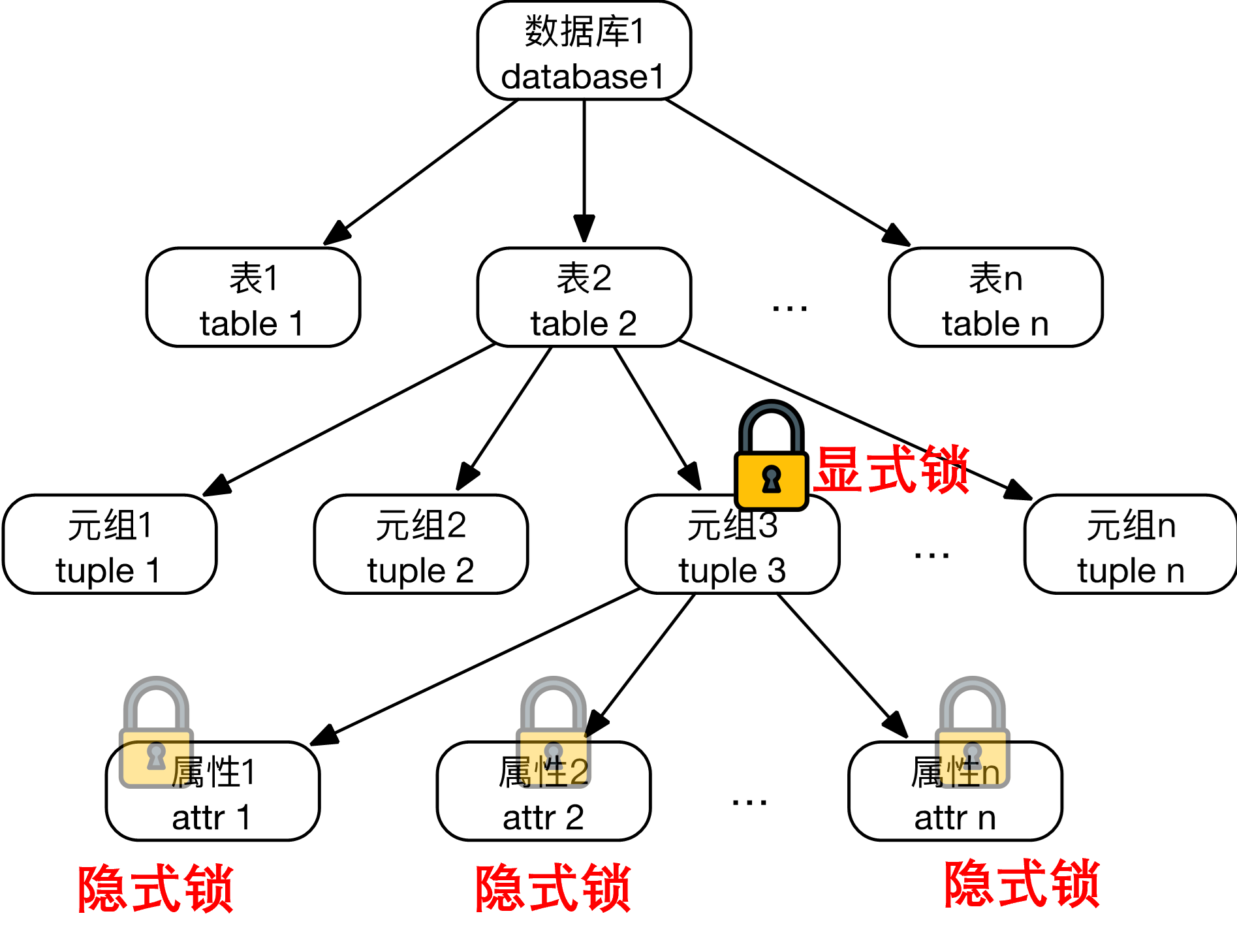
5.2.6 锁的粒度
根据被施加锁的数据项的粒度(数据库,表,记录,属性等),锁也有锁粒度(依次减小)
锁的粒度越大,数据项越少,管理锁的开销越小,事务间发生冲突的可能越大,并发度越低
多粒度锁
数据库中所有对象构成一棵多粒度树,每一个节点都可以独立加锁
对某个节点加锁表示对其后代加相同类型的锁
显示锁:该节点直接被加上的锁
隐式锁:该节点没有直接加,但是其祖先被加锁
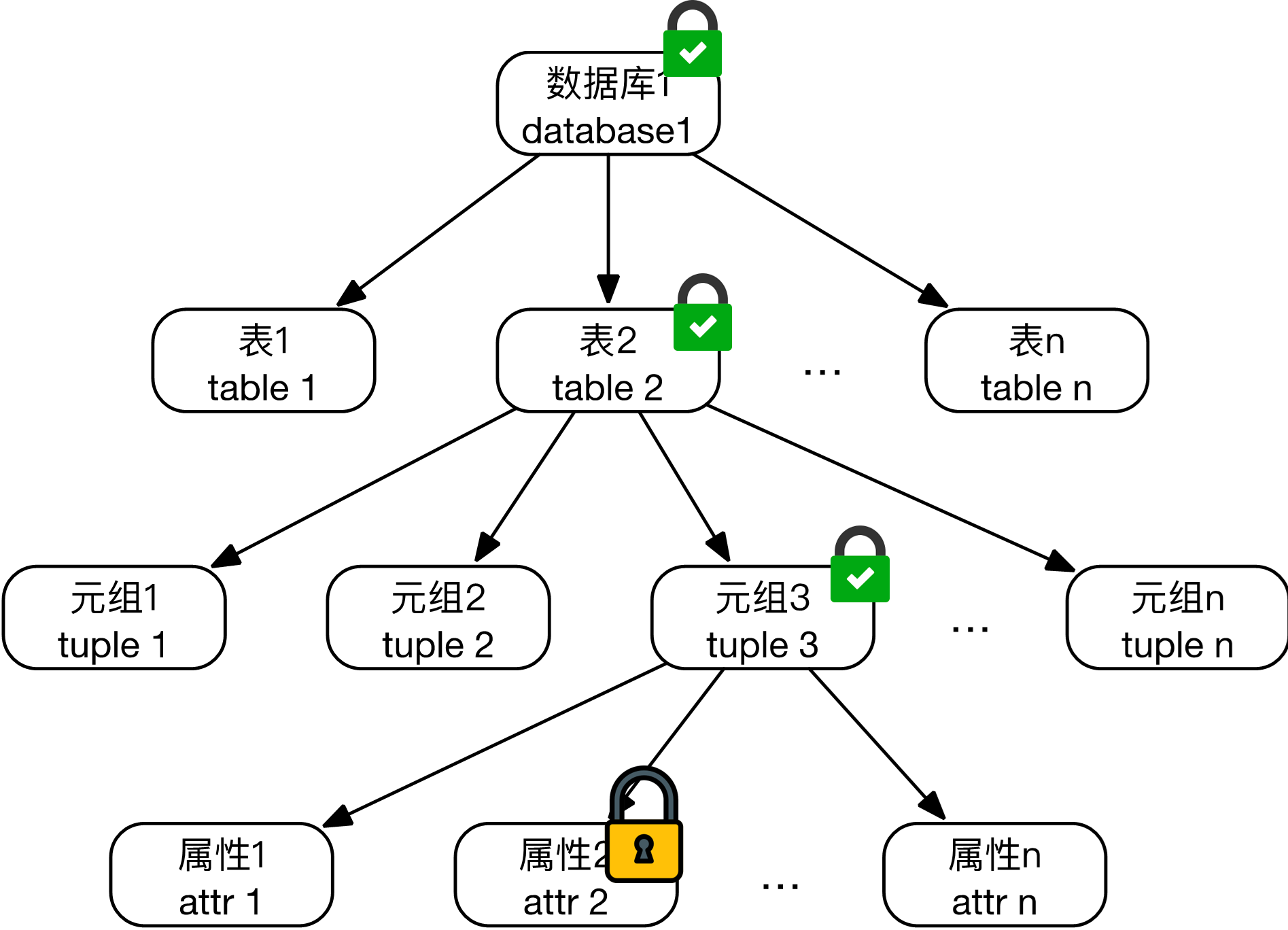
5.2.7 意向锁
对某个节点的所有祖先加的锁
意向共享锁(IS锁):某个数据加共享锁,其祖先加的这个
意向互斥锁(IX锁):某个数据加互斥锁,其祖先加这个
共享意向互斥锁(SIX锁):某个数据同时显式地加共享锁和IX锁
这些所的容斥关系如图
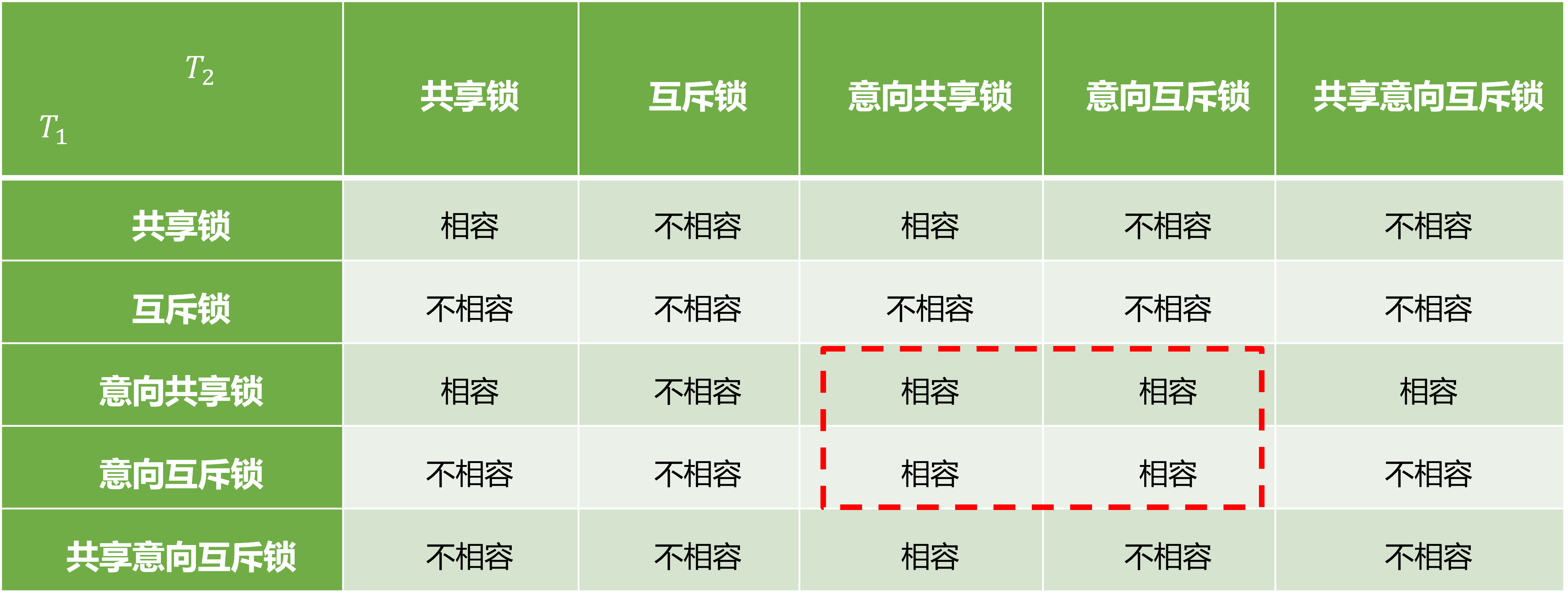
这样设计,意味着允许同时读写一个大粒度下的不同细粒度数据项,提高了并发度
5.2.8 谓词锁
作用于满足特定条件的所有对象,这个锁的施加条件比较特殊
- 事务T1想要施加谓词锁,这个锁影响的所有数据都不能存在互斥锁
- 事务T1想要给某些存在谓词锁的数据进行更改(
UPDATE,INSERT,DELETE),需要检查这些数据的旧值和新值是否满足谓词锁,满足,则需要谓词锁释放后才行
5.2.9 索引区间锁
在索引上施加的锁,用于锁定一个特定的索引键值范围
影响所有在这个范围内的索引,即使目前的表中不存在
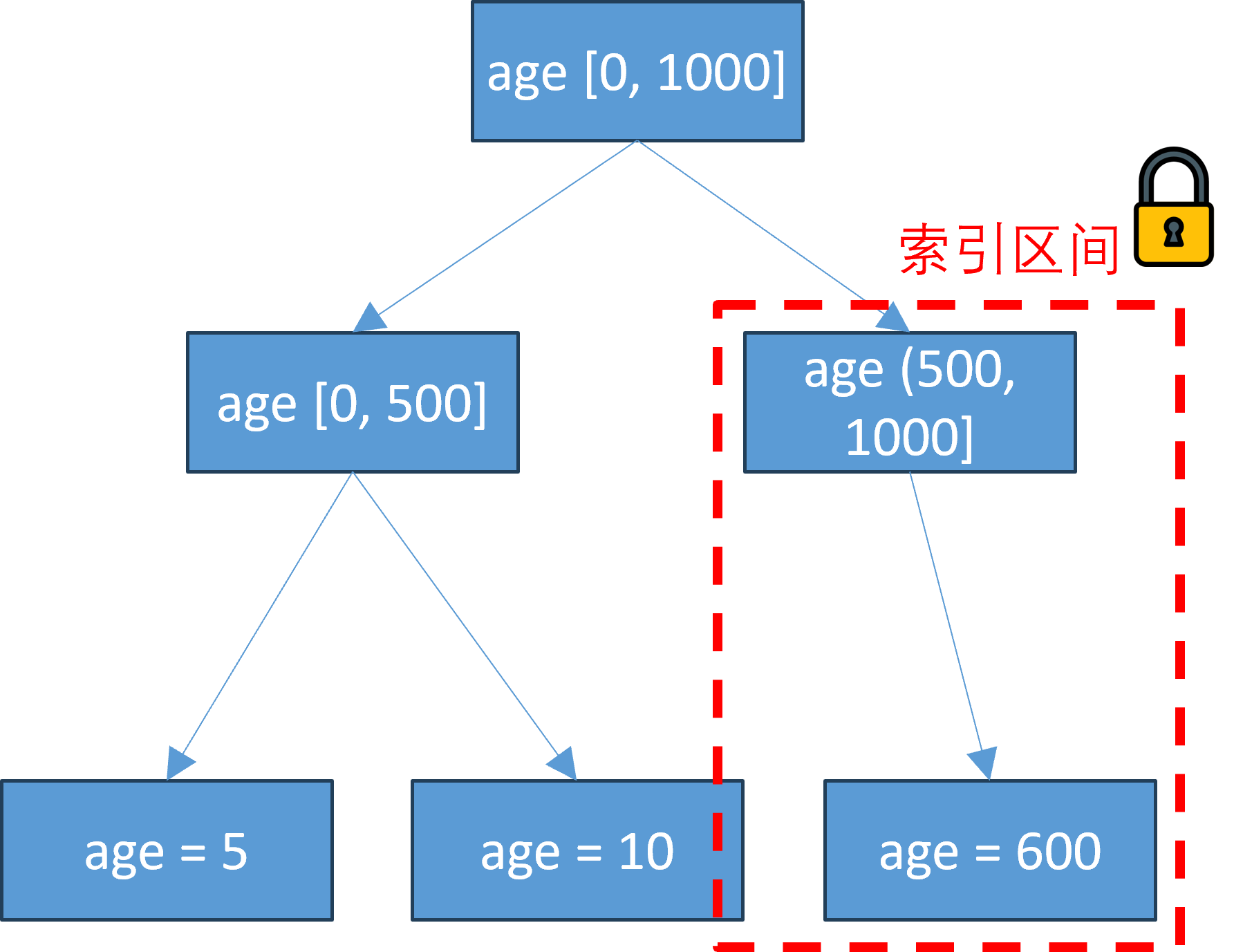
索引区间锁的检查与索引更新同步,开销不大,但是加大了锁的范围,导致更多的冲突和等待
索引区间和谓词锁是为了减少开销存在的,所有满足条件的数据项加一把锁,减少了需要的锁的数目
5.3 事务
- 原子性(A):几个操作一起做完才能提交,不可分割
- 一致性(C):转账不能出错,金额不变
- 隔离性(I):串行和并行的结果一致,互不干扰
- 永久性(D):提交完不会变
5.4 调度
事务执行的顺序(并发/串行)
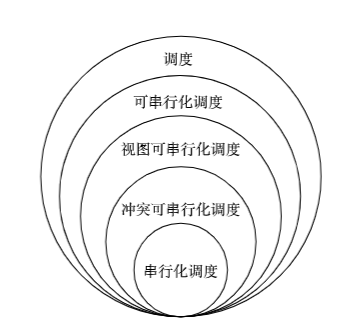
5.4.1 可串行化调度
一个并发调度\(S\),存在一个串行调度\(S^{'}\),两个效果一致;不需要锁的机制,也没有锁的问题
\(N\)个事务的串行排列一共\(N!\)种,那么判断一个调度是否可串行的复杂度为\(O(N!)\)
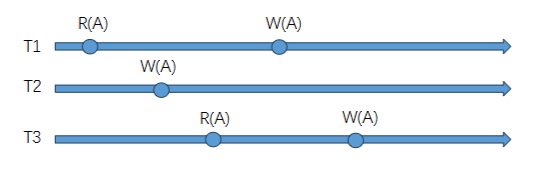
交换:不同事务的两个相邻操作交换顺序
交换后等价的情况:
- R(A), R(A)
- R(A), R(B)
- R(A), W(B)
- W(A), W(B)
非等价:
- R(A), W(A)
- W(A), W(A)
5.4.2 冲突可串行化调度
并发调度\(S\),通过等价交换可以变成可串行化调度\(S^{'}\),则是一个冲突可串行化调度
根据不等价交换的执行顺序构建一张有向图(优先图),当图中出现环时,这个调度不可串行化,即不是冲突可串行化
对于一个冲突可串行化调度,用拓扑排序可以找到一个串行化调度
5.4.3 视图可串行化调度
每个事务读取到的数据结果与某个串行化调度的结果相同
\(S\)与\(S^{'}\)的读取的\(X\)的初始值、更新值和最终写入结果相同
重画有向图
引入\(T_0=W(A)\),这是最先的操作,保证初始值一致;\(T_{n+1}=R(A)\),这是最后的操作,保证最终结果一致
如果\(T_i\)读取了\(T_j\)的变量,那么\(T_j\)指向\(T_i\)
然后通过逻辑上的先后连接没有连接但存在关系的事务
例:
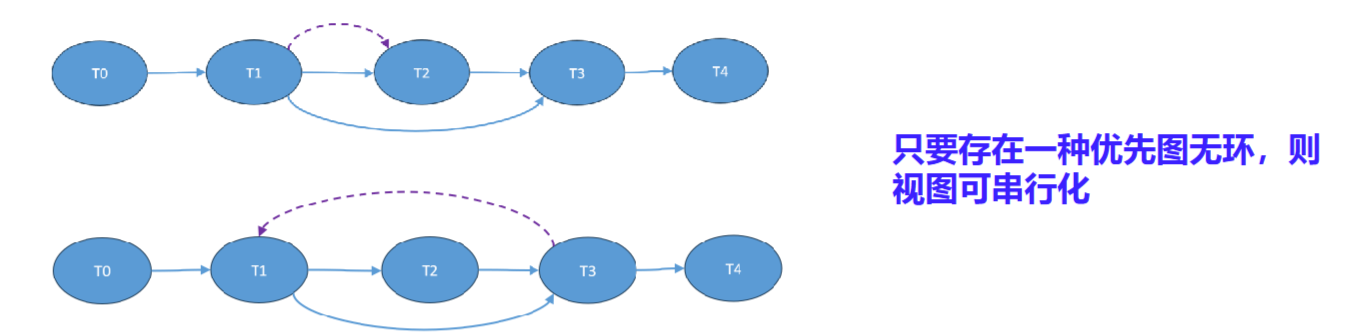
判断完第一步,得到0->1,2->3->4;判断逻辑先后,得到1->2,1->3,因为是1先执行的
然后1有w,可以放到2->3前/后,只要一种无环就行
5.5 其他并发控制机制
5.5.1 乐观并发控制技术
假设:多个事务同时操作一个数据的概率很低
分为三个阶段
- 读取:不加锁,允许其他事务访问
- 验证:准备提交时,检查事务执行过程中有无修改
- 不/存在问题:提交/回滚,重试
如何回滚?
时间戳排序协议
每个事务有唯一的时间戳,每次读写都记录这个时间点的时间戳,对比这个时间和事务的时间戳进行决定
- 事务只能读之前写的数据
- 事务只能写之前读的数据
5.5.2 多版本机制
记录多个提交的版本,最终再选择(git)