3 SQL语句
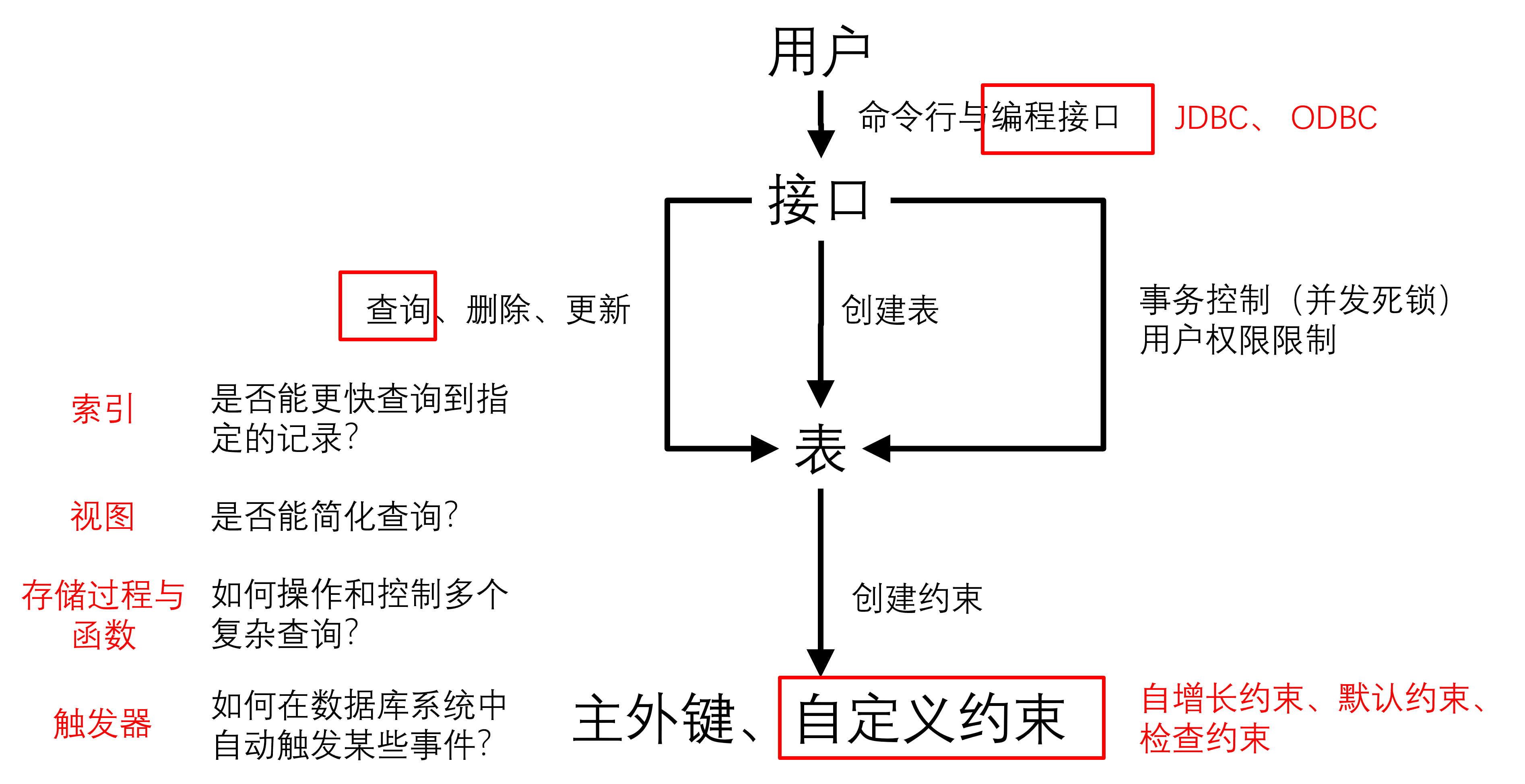
3.1 SQL查询语言分类
- 数据定义语言:定义一种关系和键
- 数据操作语言:关系运算
- 数据控制语言:定义管理权限
- 事务控制:对一个操作分步
- 存储过程和调用:编程和调包
- 触发器:事件发生后执行
3.2 SQL语句
MySql不区分大小写,即使变量名是大小写混杂的
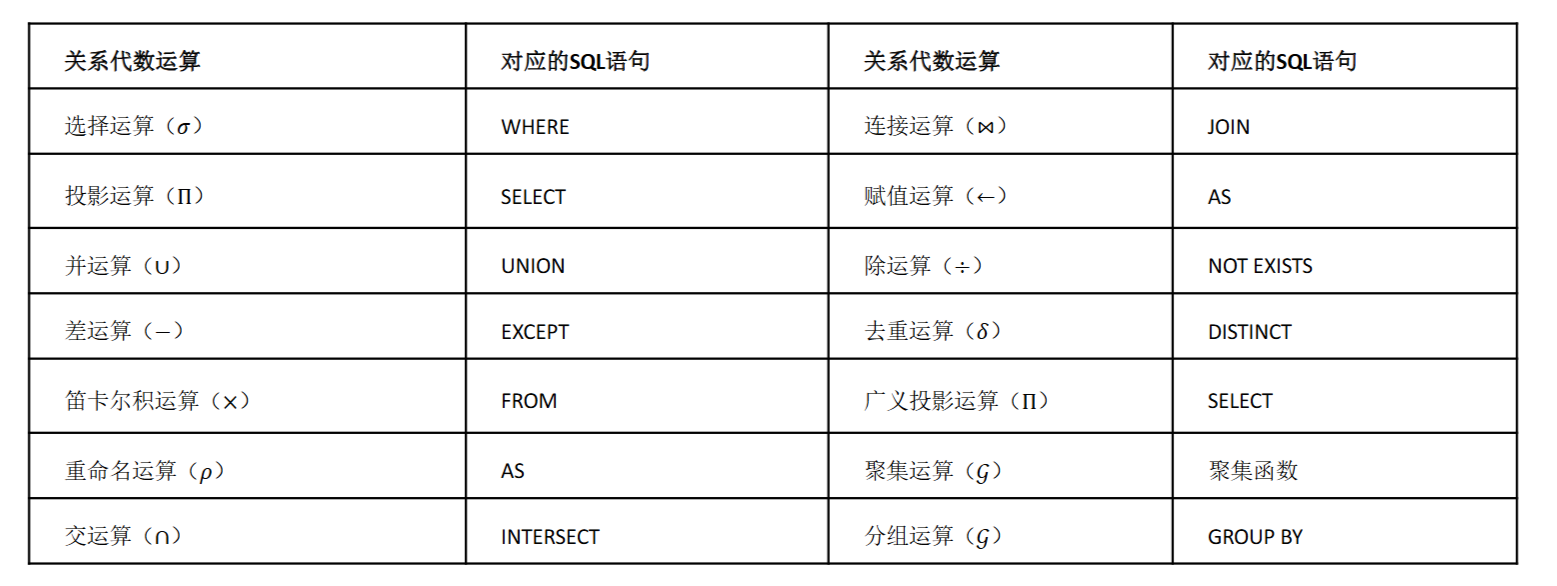
关系代数和SQL语句的关系
3.2.1 建库和表
建库并使用
create database student_db;
use student_db;
建表
create table student
(
student_id char(10) not null,
student_name varchar(50) not null,
gender char(2),
age integer,
department varchar(50),
primary key (student_id) #指明主键
unique uq_student_student_id(student_id) #唯一性约束
foreign key (course_id) references course(course_id) #外键约束,这张表没有这个属性
#仅做演示
);
使用show tables返回库中所有的表;使用desc student返回表的属性,按降序排列
修改表
alter table student add hobby varchar(50); #添加属性hobby
alter table student change column hobby interest varchar(50); #重命名hobby为interest
alter table student drop interest; #删除interest属性
alter table student add/drop foreign key FK_course_course_id;
alter table student add primary key student_id
添加属性和删除属性不对应任一个关系运算,重命名就是重命名
删除表
drop table student
当一个表的某个属性是另一个表的外键时,这个表不能直接删除
3.2.2 数据查询
select语言很强大
select student_id, student_name
from student
where department = 'CS' and student_name = 'A';
select * from student where xxx #返回所有属性
上面是一个选择,投影的操作,where语句就是选择运算
广义投影
select 2023-age as birthyear, lower(student_name)
from student
where department = 'CS';
将2023-age作为出生年份
select student_id, student_name
from student
where department = 'CS' and student_name like '%A';
like用于查询和匹配字符串,_匹配字符串中的一个任意字符,%匹配字符串中的任意个任意字符(包括0和1)
select distinct department from student;
distinct:消除重复的行,返回所有出现过的值
聚集
select count(*) from student where xxx #*指所有,返回元组数
#sum(), avg(), max(), min()同理
分组
select course_id, count(*)
from courseselection
group by course_id;
查询每门课的选课人数
select course_id, count(*)
from courseselection
group by course_id having count(*)>5
加上条件,选课人数大于5人
排序
select * from courseselection
order by grade desc;
desc是降序,asc是升序,不写默认升序
连接
select *
from student,courseselection
where student.student_id = courseselection.student_id;
一个自然连接
3.2.3 数据更新
插入
insert into student
(student_id, student_name, gender, age, department)
values ('1', 'xx', 1, 30, 'CS'), ('2', 'XA', 0, 22, 'PE');
没有出现的属性,除非有默认值,否则都认为是NULL
修改
update student
set age = 31
where student_id = '2'
没有where,所有的元组都会被修改
删除
delete from student
where xxx
没有where,表就变空表了
自增长、默认值和检查约束
create table exchangestudent
(
student_id integer not null auto_increment,
home varchar(50) default 'shanghai',
age integer check(age>0)
);
自增长一般用于主键,每次插入记录时自动生成一个唯一的数字值
默认值可以在插入数据不指明该属性值时默认填充
检查约束是用户自定义的
有时候在实践过程中也会放弃一些约束,原因是
- 某些约束太复杂,不适合在sql中验证
- 额外的性能开销在高并发下不合适
- 有些历史数据/新规则不符合约束
索引
creatr index id_index
on exchangestudent
(student_id asc);
asc升序,desc降序
drop index id_index on exchangestudent;
alter table exchangestudent drop index id_index
两种方法都能删除索引
索引的优劣
优势:提高查询速度
劣势:增加空间需求(索引占空间);插入、更新和删除的同时需要更新索引,提高性能开销;导致过度优化,还不如服务器自动优化
视图
create view total as select student.student_id as student_id, student.age as age
from student
where xxx;
创建一个名叫“total”的视图来存储信息,相当于一张表,操作和table差不多,将table换成view就行
视图是一种虚关系,实际操作还是通过定义语句对底层的table进行操作,在MySQL中对视图进行更新会对table进行更新
3.2.4 存储过程,函数和触发器
存储过程
delimiter // #注意有空格,不然编译不过的
create procedure incrementNumber (in num int, out result int, inout abc int)
begin
set result = num + 1;
end // #有空格
delimiter;
相当于一个函数,in是需要输入的变量,out是函数返回值,可以没有;inout既可以作为输入也可以作为输出,看有没有
调用过程如下
set @result = 1
call incrementNumber(5, @result);
select @result; #@result = 6
@表示这个变量是用户定义的会话变量,在这次会话结束会销毁
show procedure status where db = 'student'; #不用_db,打印所有的存储过程
drop procedure incrementNumber; #删除存储过程
declare v_counter int; #声明变量,必须紧跟在begin之后
set v_counter = 10; #变量赋值
if v_counter > 10 then
v_counter = 10
elseif v_counter < 5 then
v_counter = 5
else
v_counter = 1
end if;
存储过程中的循环定义如下
while condition do
#do something
end while;
游标
存储过程中还可以使用游标,相当于指针,在解引用后会自增,使用方法如下
declare cur_name cursor for select student_id from student order by age;
open cur_name; #打开光标
while xxx do
fetch cur_name into id, name; #存储过程的临时变量
end while; #关闭光标
close cur_name;
在fetch过后光标会自增,不需要手动操作
光标也可以用很复杂的函数,如
declare cur cursor for
select student_id, AVG(grade) as avg_grade
from courseselection
group by student_id
having avg_grade > 80;
函数
delimiter //
create function addTwoNumbers(a int, b int)
returns int
deterministic
begin
return a + b
end //
delimiter;
select addTwoNumbers(5, 3); #返回8
返回的是结果单值,不是一个集合
存储过程和函数的区别
- 存储过程可以是out/inout组成的一个集合,函数只能是return语句声明的值
- 函数的参数只能in
- 存储过程通过call调用,函数可以在查询语句中调用
- 函数内必须要有一个returns
触发器
DELIMITER //
create trigger name
after insert on student
for each row
begin
#触发体动作
end;
//
DELIMITER ;
其中after表示在student这张表发生insert之后,执行触发器内容,也可以是before
对于作用的每一行(for each row),都会执行触发体动作,在触发事件之前的该行内容是OLD,之后是NEW
可以这样访问
new.student_id;
old.course_id
当是修改一行内容时,存在old和new;当是插入一行时,只有new,指代新插入的那行
触发器可以认为是特殊的存储过程,但是触发器只允许数据操作行为,不允许建表,指定主键等定义行为,而触发器可以
因此,当触发器需要数据定义时,可以调用对应的存储过程
3.2.5 事务控制
start transaction
指定一个事务的开始
commit
指定事务的结束
rollback
回退所有操作,直到最近的标记点,若无标记点则回退到start transaction,类似于撤销
savepoint sp_name
设置回退标记点
release savepoint sp_name #删除标记点
rollback to sp_name #退回到这个点
3.2.6 用户权限控制
create user 'username'@'hostname' identified by 'password'; #创建用户
drop user 'username'@'hostname'; #删除用户
select user, host from mysql.user #查看用户
grant insert #授予insert的权限
on table student_db1.student #在这个库的这个表
to '123'@'localhost' #给这个用户
with grant option; #可以给别人这个权限
revoke insert #回收权限
on table student_db1.student
from '123'@'localhost'; #mysql不支持级联回收,123给出去的权限收不回来