6 两个、多个变量之间的关系
6.1 相关性分析
6.1.1 协方差
某个样本有两个变量,记为\(X,Y\),其观测值记为\(x_i,y_i\),则\(x,y\)的协方差为
\(\text{cov}(x,y)=\frac{\sum_{i}(x_i-\overline{x})(y_i-\overline{y})}{n-1}\),n-1是无偏估计
注意在概统中曾经提过的协方差\(\text{cov}(X,Y)=E(\sum_i(X_i-\overline{X})(Y_i-\overline{Y}))\)是总体的,所以不除\(n-1\)
python代码
data是一个dataFramedata[["obj1","obj2"]].cov()
很显然\(cov(2x,2y)=4cov(x,y)\),即协方差受量纲的影响,为了解决这个问题,使用相关系数
6.1.2 相关系数
以下三个相关系数,只需且只能算一个
6.1.2.1 Pearson's linear(Pearson 相关系数)
\(r_{x,y}=\frac{cov(x,y)}{s_x\cdot s_y}=\frac{\sum_i(x_i-\overline{x})(y_i-\overline{y})}{\sqrt{\sum_i(x_i-\overline{x})^2\sum_i(y_i-\overline{y})^2}}\)
其中\(\sigma\)是各自的样本方差,除以样本方差后变为无量纲的量
经验上将\(|r|\)分为以下三类
- 0.1~0.3, Small
- 0.3~0.5, Medium
- \(>\)0.5, large
r对outlier很敏感,r是数据分布是否线性的判断;r=0仅能说明线性关系弱,不是没有关系
python代码
r, p = stats.pearsonr(data.obj1, data.obj2)返回两个量,r是相关系数,p是对相关系数做r=0的NHST的p
data.corr(method="pearson")
对整个dF求相关系数
6.1.2.2 Spearman's \(\rho\)
使用情况:
- X,Y不是数值,而是一个排序的变量,or
- X,Y没有明显的线性关系
首先将原始的\((x_i,y_i)\)排序,用排序后的顺序作为新的值,带入\(r_{x,y}\)的公式计算
用于评估单调关系
例:X[5,2,8,1,4];Y[10,4,12,3,8]
首先排序,得到新的:R[3,2,5,1,4];S[4,2,5,1,3],对应的\((r_i,s_i)\)不变
如果有相同的,就并列,如R[1,2,2,4,5]
而平均值就是排序后正常计算的平均值,用新的数组带入上述公式
def \(d_i=R_i-S_i\),则有
\(\rho=1-\frac{6\sum_id_i^2}{N(N^2-1)}\),其中N是样本观测量,上例中N=5,和上式计算结果一致
python代码
r, p = spearmanr(data.obj1, data.obj2)返回两个量,r是相关系数,p是对相关系数做r=0的NHST的p
data.corr(method="spearman")
对整个dF求相关系数
6.1.2.3 Kendall's \(\tau\)
使用情况:
- X,Y不是数值,而是一个排序的变量,or
- X,Y没有明显的线性关系

python代码
r, p = kendalltau(data.obj1, data.obj2)返回两个量,r是相关系数,p是对相关系数做r=0的NHST的p
6.1.3 相关系数的置信区间估计,NHST
用样本观测值得到的样本相关系数,可以推测总体相关系数的区间
实际上为了得到总体的相关系数也只能这么做
使用Fisher-z变换修正偏度,得到以下表格
| Fisher-z | CI of z | CI we need | |
|---|---|---|---|
| Pearson’s r | \(z_r=\frac{1}{2}\ln{\frac{1+r}{1-r}}\) | \(z_r\pm z_{\alpha/2}\sqrt{\frac{1}{n-3}}\) | \(r_L=\frac{e^{2z_{L}}-1}{e^{2z_{L}}+1},r_U=\frac{e^{2z_{U}}-1}{e^{2z_{U}}+1}\) |
| Spearman's \(\rho\) | \(z_{\rho}=\frac{1}{2}\ln{\frac{1+\rho}{1-\rho}}\) | \(z_\rho\pm z_{\alpha/2}\sqrt{\frac{1+\rho^2/2}{n-3}}\) | \(\rho_L=\frac{e^{2z_{L}}-1}{e^{2z_{L}}+1},\rho_U=\frac{e^{2z_{U}}-1}{e^{2z_{U}}+1}\) |
| Kendall's \(\tau\) | \(z_{\tau}=\frac{1}{2}\ln{\frac{1+\tau}{1-\tau}}\) | \(z_\tau\pm z_{\alpha/2}\sqrt{\frac{0.437}{n-4}}\) | \(\tau_L=\frac{e^{2z_{L}}-1}{e^{2z_{L}}+1},\tau_U=\frac{e^{2z_{U}}-1}{e^{2z_{U}}+1}\) |
注意,求得的置信区间是非对称的
6.1.4 Pearson's r相关分析假设条件
- 两个连续变量(或近似于连续)
- 描述线性关系
- 没有异常值outlier
- 相关性不等于因果性;p值不反应总体的相关性
- 观测值相互独立
6.1.5 APA报告
Pearson相关分析表明,两个变量之间存在很强/中等/弱/没有线性相关性(r(N)=.30,p<.001,95%CI=[0.15,0.35])
N是样本观测量
6.2 简单线性回归分析
根据样本值,建立一阶线性模型\(Y=\beta_0+\beta_1X\),要求XY都是连续变量
实际上,根据有限的样本值得到的样本观测模型为\(y_i=b_0+b_1x_i+\epsilon_i\),其中\(\epsilon_i\)为第i组观测值的误差,\((x_i,b_0+b_ix_i)\)为第i组回归值/预测值
注意,每一组样本值都应该独立
例:建立物理成绩和数学成绩的简单回归模型,下面的计算结果都是正确的,问哪个说法是正确的
- 某同学,数学80分的,建议推断其物理成绩是80分
- 数学成绩为80分的同学,物理平均分为82分
- 可以通过提高数学成绩,来提高物理成绩
- 一组学生经过训练,数学成绩提高5分,则平均物理成绩提高约4.5分
- 数学成绩平均为90分的学生比数学成绩平均80分的学生,物理成绩平均高9分
正确的是标红的;不能推断单个;不能推断一个样本的变化
6.2.1 估计样本回归模型
为了得到\(y=b_0+b_1x\),需要进行线性拟合,这里使用最小二乘法(Ordinary Least Square)
预测值\(\hat{y_i}=b_0+b_1x_i\),误差\(\epsilon_i=y_i-\hat{y_i}=(y_i-b_0-b_ix_i)\)
def 样本整体预测误差(sum of squared errors)\(\text{SSE}=\sum_i(y_i-\hat{y_i})^2\)
\(b_0,b_1\)要使得SSE最小,则\(\frac{\part\text{SSE}}{\part b_0}=\frac{\part\text{SSE}}{\part b_1}=0\)
\(\Rightarrow b_0=\bar{y}-b_1\bar{x},b_1=\frac{n\sum_i{x_iy_i}-\sum_ix_i\sum_iy_i}{n\sum_ix_i^2-(\sum_ix_i)^2}=\frac{\text{COV(x,y)}}{\text{D}(x)}\)
注意\(b_i\)的第二种算法使用的是计算总体的方法,即\(/n\)而非\(/(n-1)\),当然用样本的计算结果是一致的
得到样本回归模型\(y=b_0+b_1x\),注意这只能表示观测对象和自变量的关系,对观测值不适用
6.2.2 总体模型
由样本推总体无非是CI和NHST

得到\(\beta_0和\beta_1\)的CI,注意t分布的自由度是n-2,因为使用样本估计了方差(n-1-1)
python代码
LR = stats.linregress(data.obj1,data.obj2)在残差正态性下,依次输出
slope,斜率,即b1
intercept,截距,即b0
rvalue,两个变量的r相关系数
pvalue,b1=0做NHST得到的p
stderr,b1的标准误差,不是标准差
intercept_stderr,b0的标准误差
为了使X=0时的Y有意义,即为了x=0时截距有意义,一般会将X做随机变量中心化,此时截距的意义就是X为平均值时的Y值;做随机变量标准化是为了解决量纲的影响
6.2.3 模型误差估计
6.2.3.1 均值CI(CIB)
每个观测值x处,对应的y(多个)的均值\(\hat{y}\)的CI,有\(\hat{y}_{ci}=\hat{y}\pm t_{\alpha/2}(n-2)\cdot \sqrt{MSE}\cdot \sqrt{\frac{1}{n}+\frac{(x-\bar{x})^2}{\sum_i(x_i-\bar{x})^2}}\)
其中\(MSE=\frac{\sum(y_i-\hat{y_i})^2}{n-2}\)
注意这是\(\hat{y}\)在x处的CI
6.2.3.2 观测值CI(PIB)
每个观测值x处,对应的观测值y的CI,有\({y_{pi}}=\hat{y}\pm t_{\alpha/2}(n-2)\cdot \sqrt{MSE}\cdot \sqrt{1+\frac{1}{n}+\frac{(x-\bar{x})^2}{\sum_i(x_i-\bar{x})^2}}\)
MSE见上
python代码
import statsmodels.formula.api as smfmodel = smf.ols("Height~Weight", data=data)
results = model.fit()
其中results.summary()函数会给出报告
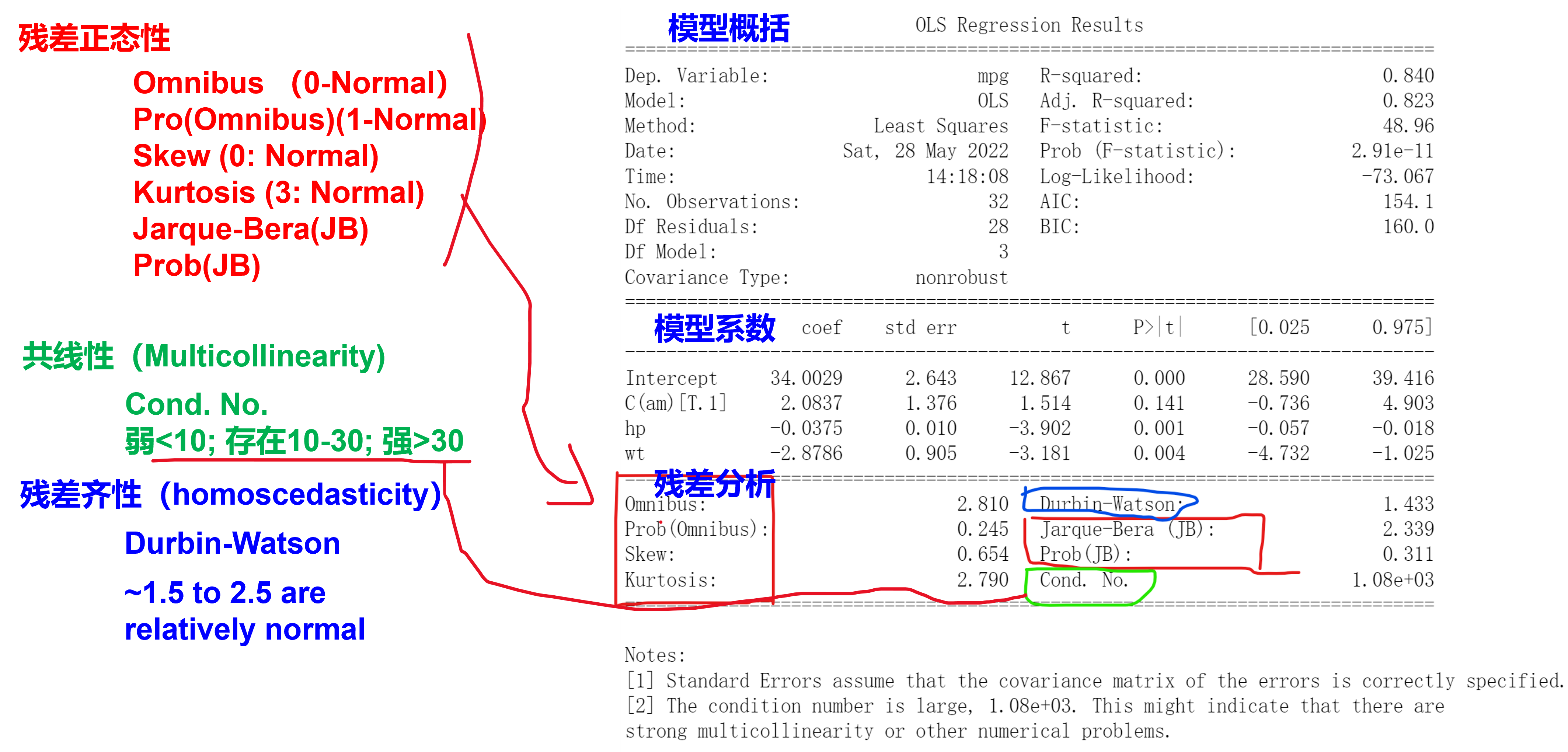
当共线性很强(残差线性相关)时,模型不能用来解释变量之间的关系(拟合地不好),但是仍然能用于预测数值
NHST的零假设是bi=0;当残差的方差过大时,模型不能用来预测,但是解释的效果可以
6.2.4 一阶线性回归模型的假设
- X,Y都是连续变量
- Y随X线性变化
- 残差正态性,\(\epsilon \sim N(0,\sigma^2)\)
- 所有数据i.i.d.
- 自变量在同一个level上
6.2.5方差分析
定义\(SST=\sum_i(y_i-\bar{y})^2=\sum_i(y_i-\hat{y_i}+\hat{y_i}-\bar{y})^2=\sum_i(y_i-\hat{y_i})^2+\sum_i(\hat{y_i}-\bar{y})^2+2\sum_i(y_i-\hat{y_i})(\hat{y_i}-\bar{y})\)
当满足OLS时,第三项=0,定义\(SSR=\sum_i(\hat{y_i}-\bar{y})^2\),\(SSE=\sum_i(y_i-\hat{y_i})^2\)
故\(SST=SSR+SSE\),SSR是自变量能解释的SS,SSE是自变量不能解释的SS(Error)
定义\(R^2=\frac{SSR}{SST}=1-\frac{SSE}{SST}\)
代入定义式有\(R^2=\frac{\sum_i(\hat{y_i}-\bar{y})^2}{\sum_i(y_i-\bar{y})^2}\),又\(\hat{y_i}=b_1x_i+b_0\),最终得到\(r(x,y)=\pm\sqrt{R^2}\)
又有\(r(x,y)=\frac{\text{COV}(x,y)}{\sqrt{\text{D}(x)\text{D}(y)}},b_1=\frac{\text{COV}(x,y)}{\text{D}(x)}\)
\(\therefore b_1=r(x,y)\cdot\frac{\sqrt{\text{D}(y)}}{\sqrt{\text{D}(x)}}\)
当然用样本方差也行,因为n都除掉了,实际上r使用样本的量来计算得到的结果也是一致的
故可以根据两个变量的均值,方差,R2来估计线性回归模型
R2越大,模型预测越准确
6.3 多元线性回归模型(MLR)
连续的观测量与多个因变量的关联:\(SBP_i=b_0+b_1x_{1i}+b_2x_{2i}+\ldots+\epsilon_i\),线性指的是系数(bi)是线性的,而非自变量,如\(y=b_0+b_1x+b_1x^2\)也是线性回归模型
而一般线性回归模型(GLM)通常还有一个类别变量
同样的,MLR也是用最小二乘法估计

这也导致outlier的干扰很大
python代码
model = smf.ols("Height~Weight+GymTime", data=data)在这里用+连接自变量 results = model.fit()
print(results.summary())
报告格式和一阶模型一致
- 无交互作用,\(y=b_0+b_1x_1+\ldots+b_nx_n\)
在解释系数时,不能说单个样本的变化,而是总体的差异
报告给出的t检验的\(H_0:b_i=0\),即因变量和这个因素无关
- 存在交互作用,\(y=b_0+b_1x_1+b_2x_2+b_3x_1x_2\)
\(b_1,b_2\)的涵义变化为其他自变量为0时,该变量的影响
\(b_3\)可以这么看:\(y=b_0+b_1x_1+(b_2+b_3x_1)x_2\)
即x2的系数与x1有关,在不同的x1水平下,x2对y的作用存在变化,\(x_1,x_2\)存在交互作用
b3可以认为是两组差异的差异
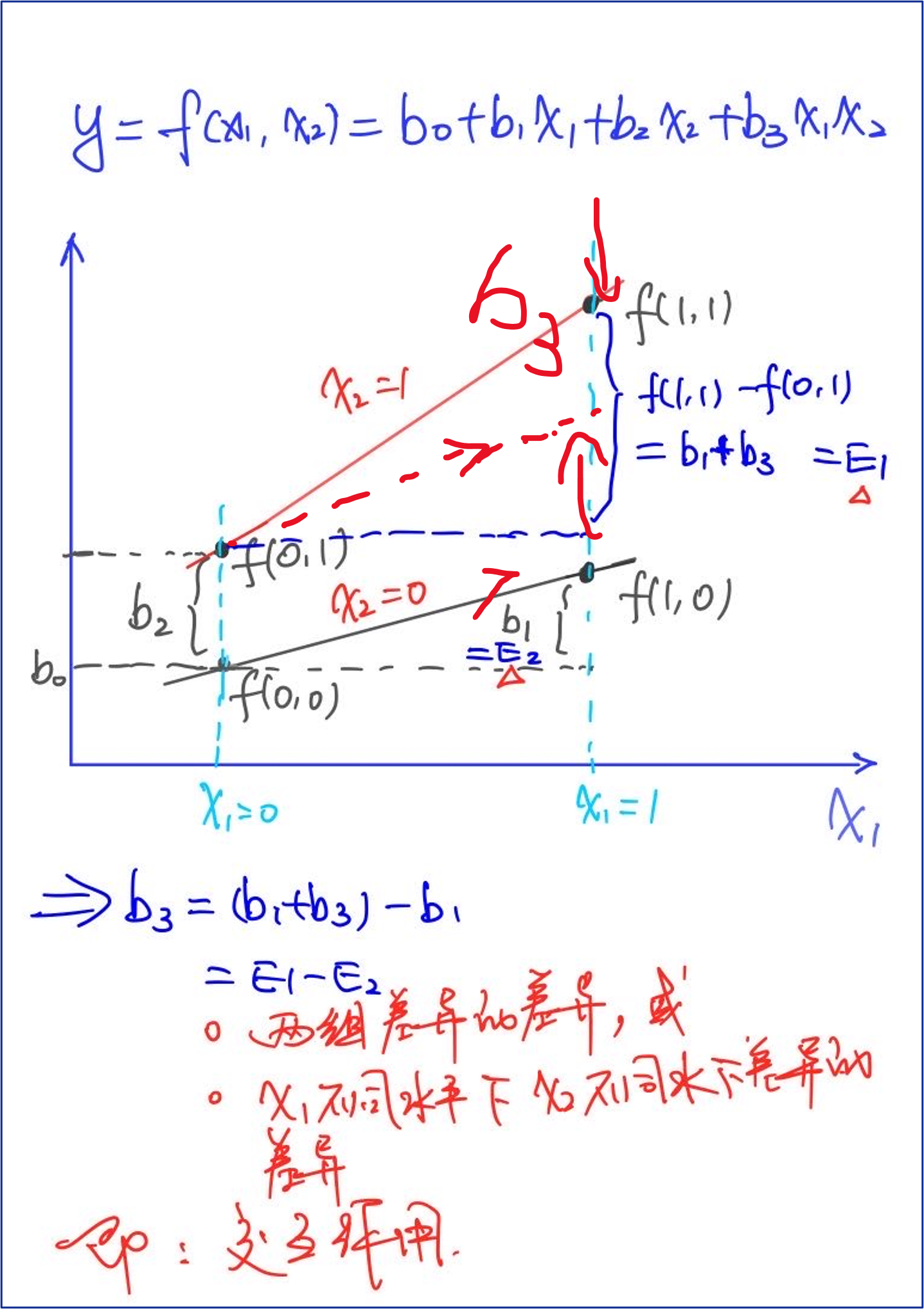
如要说明某种新药的显著性,也是用上面的方法
即枢轴量不使用\(f(1,1)-f(1,0)\),而使用\(b_3=[f(1,1)-f(0,1)]-[f(1,0)-f(0,0)]\),即差异的差异
这也说明,如果两条线不平行,那么说明可能存在交互作用
6.3.2 模型评价
6.3.2.1 残差特性
类似于6.2.3.2
好的模型,残差特性有
正态分布性:
- Jarque-Bera检验的零假设是数据服从正态分布,备择假设是数据不服从正态分布
它基于样本的skewness和kurtosis来进行检验
- Jarque-Bera检验的零假设是数据服从正态分布,备择假设是数据不服从正态分布
自相关性弱:残差的值是否独立,是否有\(\epsilon_{i}=f(\epsilon_{i-1})\),不是一般意义上的两个变量相关
- 当Durbin-Watson统计量接近2时(1.5~2.5),表示残差不存在自相关性(即残差之间相互独立)
- 当Durbin-Watson统计量接近0或4时,表示存在正向或负向的自相关性
共线性弱:即残差之间线性无关;当残差共线性强时,说明模型漏了某些解释变量
方差齐性:数据不是喇叭口状的,在x不同水平下残差的范围比较一致
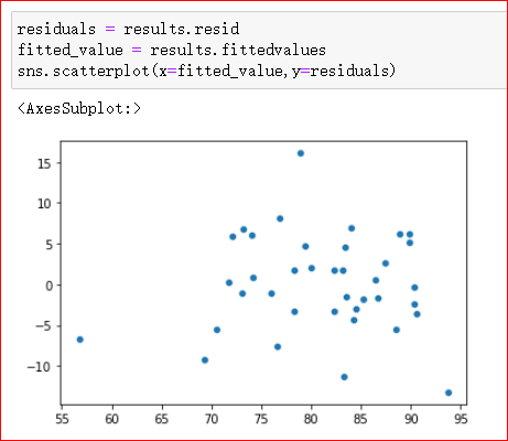
好的残差分布,已经归一化
6.3.2.2 总体评价
包括\(R^2\),Adjusted \(R^2\),AIC,BIC,F-value,P-value
\(R^2=\frac{SSR}{SST}=1-\frac{SSE}{SST},R^2_{adj}=1-\frac{(1-R^2)(n-1)}{n-p-1}\)
其中n为样本大小,p为自变量个数
当自变量数量变多,Adj R2会减小,模型存在过拟合风险
模型总体的显著性为F-value
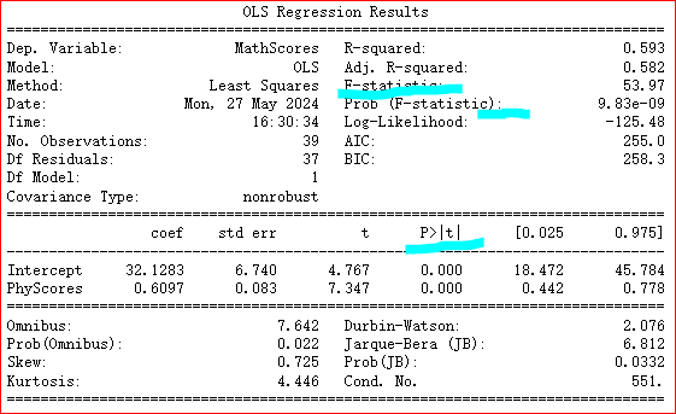
R2是服从F分布的,自由度不用管,F-value是优先于T-value的,当模型的F-value不足时,t的P值再显著,也不太有效,t的P值是H0:bi=0的NHST检验值
AIC与BIC
AIC从预测角度,表明模型对未知数据的预测程度,AIC越小,意味着模型更简洁和精确
BIC从拟合角度,表明模型对当前数据的拟合程度,BIC越小,意味着模型更更简洁
6.3.3 模型汇报
最好用表格
文字的APA:
Social support significantly predicted depression scores(bi= -.34, t(225) = 6.53, p< .001)
也要汇报R2,F,p
Social support also explained a significant proportion of variance in depression scores(R2 = .12, F(1, 225) = 42.64,p< .001)
如果模型有显著的交互作用,主效应的解释要谨慎,因为主效应可能是交互作用引起的
模型描述的变量间的关联性,避免把结果解释成因果性
大的R2值不一定好的模型,同样小的R2不一定是差的模型
6.3.4 实际使用的优化方法
数据可视化:pairplot/scatterplot/jointplot, 发现存在相关性的变量(predictors)
物理原理/实际问题:根据实际问题选取存在相关性的变量
数据驱动的模型选择(比较常用,但需要谨慎)
- Stepwise 选择: 增、减变量,观察AIC/BIC,\(R_{adj}^2\)值的变化,朝增加\(R_{adj}^2\)方向, AIC/BIC减小的方向选择
模型评价:看残差特征