4 均值的比较
4.1 置信区间 confidence interval(CI)
4.1.1 单样本
4.1.1.1 单样本总体方差已知,用Z分布
对正态总体或近似正态总体,有
\[\frac{\overline{x}-\mu}{\sigma / \sqrt{n}}\sim N(0,1)\]
若要求置信度为\(1-\alpha\),则
\[\therefore P(-u_{\frac{\alpha}{2}}<\frac{\overline{x}-\mu}{\sigma / \sqrt{n}}\leq u_{\frac{\alpha}{2}})=1-\alpha\]
\[\Rightarrow \mathsf{CI}_{1-\alpha}=(\overline{x}-u_{\frac{\alpha}{2}}\frac{\sigma}{\sqrt{n}},\overline{x}+u_{\frac{\alpha}{2}}\frac{\sigma}{\sqrt{n}})\]
4.1.1.2 单样本总体方差未知,用t分布
\[\frac{\overline{x}-\mu}{s / \sqrt{n}}\sim t(n-1)\]
\[\therefore P(-t_{\frac{\alpha}{2}}<\frac{\overline{x}-\mu}{s / \sqrt{n}}\leq t_{\frac{\alpha}{2}})=1-\alpha\]
\[\Rightarrow \mathsf{CI}_{1-\alpha}=(\overline{x}-t_{\frac{\alpha}{2}}\frac{s}{\sqrt{n}},\overline{x}+t_{\frac{\alpha}{2}}\frac{s}{\sqrt{n}})\]
4.1.2 双样本
4.1.2.1 双样本是配对的(非独立样本)
何为配对:
同一批人的两次成绩差的均值、双胞胎之间的身高差均值等,可以找到配对的双方的量
等价于单样本的分布,参见上方4.1.1
4.1.2.2 两个独立样本,总体方差各自已知
已知\(\sigma^2_1,\sigma^2_2\),要求\(\overline{x_1}-\overline{x_2}\)的置信区间
\[\therefore \overline{x_1}-\overline{x_2} \sim N(\mu_1-\mu_2,\frac{\sigma^2_1}{n_1}+\frac{\sigma^2_2}{n_2})\]
记\(\frac{\sigma^2_1}{n_1}+\frac{\sigma^2_2}{n_2}=\sigma^2=sem^2\),称其为\(\overline{x_1}-\overline{x_2}\)的标准方差,也称标准误差的平方
\[\therefore \frac{(\overline{x_1}-\overline{x_2})-(\mu_1-\mu_2)}{\sigma} \sim N(0,1)\]
\[\Rightarrow \mathsf{CI_{1-\alpha}}=(\overline{x_1}-\overline{x_2})\pm u_{\frac{\alpha}{2}}\sqrt{\frac{\sigma^2_1}{n_1}+\frac{\sigma^2_2}{n_2}}\]
4.1.2.3 两个独立样本,总体方差未知但相等
已知\(\sigma^2_1=\sigma^2_2=\sigma^2\),但是多少不知道
使用t分布
\[\therefore \overline{x_1}-\overline{x_2} \sim N(\mu_1-\mu_2, \frac{\sigma^2}{n_1}+\frac{\sigma^2}{n_2})\]
\[\Rightarrow \frac{(\overline{x_1}-\overline{x_2})-(\mu_1-\mu_2)}{\sigma \sqrt{\frac{1}{n_1}+\frac{1}{n_2}}} \sim N(0,1)\]
\[\because \frac{(n_1-1)s^2_1}{\sigma^2} \sim \chi^2 (n_1-1),\frac{(n_2-1)s^2_2}{\sigma^2} \sim \chi^2 (n_2-1)\]
\[\therefore \frac{(\overline{x_1}-\overline{x_2})-(\mu_1-\mu_2)}{\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}\sqrt{\frac{(n_1-1)s^2_1+(n_2-1)s^2_2}{n_1+n_2-2}}} \sim t(n_1+n_2-2)\]
def \(\sqrt{\frac{(n_1-1)s^2_1+(n_2-1)s^2_2}{n_1+n_2-2}}=s_p\),\(\overline{x_1}-\overline{x_2}\)的标准误差为\(sem=s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}\)
\[\therefore \frac{(\overline{x_1}-\overline{x_2})-(\mu_1-\mu_2)}{s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}} \sim t(n_1+n_2-2)\]
\[\Rightarrow \mathsf{CI}_{1-\alpha}=(\overline{x_1}-\overline{x_2})\pm t_{\frac{\alpha}{2}}(n_1+n_2-2)s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}\]
4.1.2.4 两个独立样本,总体方差未知且不相等
使用Welch's t分布
推导过于复杂,直接给出结论
\[\mathsf{CI}_{1-\alpha}=(\overline{x_1}-\overline{x_2})\pm t_{\frac{\alpha}{2}}(\nu)\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}\]
其中\(\nu\)为t分布的自由度,通常不是整数,用最接近的整数计算,有
\[\nu=\frac{(\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2})^2}{\frac{1}{(n_1-1)}(\frac{s_1^2}{n_1})^2+\frac{1}{(n_2-1)}(\frac{s_2^2}{n_2})^2}\]
4.2 零假设检验 Null Hypothesis Significance Test(NHST)
NHST注意事项
含义
NHST的含义仅仅是\(\mathsf{P}(x>\mathsf{Data}|H_0)\)
- 只反应数据和假设的兼容性
- 不能推断\(H_0,H_1\)成立的概率
- 不能直接回答真正关心的问题:\(\mathsf{P}(H_0|\mathsf{Data})\)
统计显著性α不等于实际显著性
- n足够大时,尽管差距很小,p仍然可以很小
- p很小不代表实际差距很大
常见错误:
- p值之间的比较:两组实验组,分别和对照组求p,p=0.04的结果要比p=0.05的结果更显著吗?不
- 只做了一次实验就不能讲概率
p值到底反映了什么?
- p<0.05,说明两个样本均值差异有显著性(在0假设成立的情况下)
- p<0.05,说明两个总体均值存在差异的显著性很大?错误
- “认为0假设错误”这个结论错误的概率小于p值
4.2.1 NHST与CI的关系
- NHST的回答比CI简洁,只回答Yes or No
- NSHT没有CI准确,CI还提供大/小多少的信息
- NSHT要回答的问题都可以用CI回答
4.2.2 NHST的推理逻辑
详见概统笔记
- 先做零假设和备择假设
- 什么样的假设可以作为零假设
- 假设完可以确定枢轴量的分布
- 用想要拒绝的做假设
- 不能用p不够小来确定其成立
- 选择枢轴量
- 根据枢轴量在\(H_0\)成立时的分布,根据检验方式算概率(p值)
- 双边检验:\(p=P(|x|\geq|X|)\)
- 右侧检验:\(p=P(x\geq X)\)
- 左侧检验:\(p=P(x\leq X)\)
- 检验p的显著性水平,如果p<α,则拒绝原假设,\(H_1\)成立
4.2.3 单样本t检验
总体\(\sigma^2\)未知,使用t分布
拒绝域是同α下CI的补集
python代码click
t,p=stats.ttest_1samp(a,b, altenative="two-sided")a,b输入数据,mu是零假设的均值,alternative选择检验方式
输出t是枢轴量的观测值,p是p值
一个错误例子:现有A(mean=12),B(mean=8),得到t(29)=xxx,p<.05,认为A的均值显著大于B
错误:只能认为\(\mathsf{mean(A)}\neq \mathsf{mean(B)}\),因为做的是双侧检验,无法得出单边结论。存疑
4.2.4.1 配对的样本
配对做差,和单样本相同
python代码click
t,p=stats.ttest_rel(a,b,alternative)data输入数据,alternative选择检验方式,默认mu=0
输出t是枢轴量的观测值,p是p值
4.2.4.2 独立的样本
和单样本类似的,拒绝域都是相应的α下的CI的补集
python代码click
t,p=stats.ttest_ind(data1,data2,equal_val,alternative)data1,2是数据输入,equal_var选择方差是否相同,alternative选择检验方式,默认mu=0
输出t是枢轴量的观测值,p是p值
4.3 对方差分析(ANOVA)
4.3.1 从t检验到ANOVA检验
有n组数据,两两之间做t检验(多重检验),重复m次,假设每两组、每次检验的假阳性(去真错误,第一类)概率为α,那么所有检验结后有假阳性的概率是:
\[P=1-(1-\alpha)^{\mathsf{C}^2_n\cdot m}\]
这是非常大的一个数,所以抛弃多重检验
4.3.2 ANOVA原理
假定分为k组,共N个对象,每组N/k个
ANOVA做F检验,其核心是SST=SSB+SSW(Total=Between+Within),注意自由度,证明见下
 |
 |
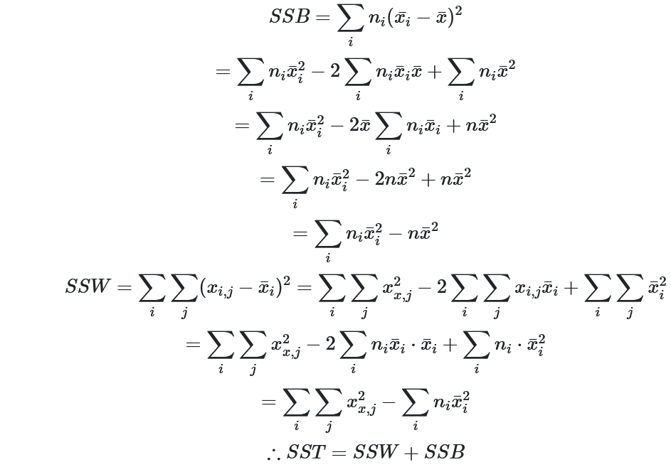 |
得到ANOVA的报告表
| Source | SS | df | MS | F | p-value | eta2 |
|---|---|---|---|---|---|---|
| Total | SSB+SSW | N-1 | / | MSB/MSW | F(k-1,N-k)对应的p | SSB/SST |
| Between | SSB | k-1 | MSB | / | / | / |
| Within | SSW | N-K | MSW | / | / | / |
其中MS=SS/df,\(\mathsf{F}(df_B,df_W)=\frac{MSB}{MSW}=\frac{SSB/df_B}{SSW/df_W}\)
\(\eta^2=\frac{SSB}{SST}\),表示SST中有多少是SSB贡献的,也叫effect size
4.3.3 单因素对方差分析 1-Way ANOVA
类似于下面的分组,每组的受试样本都是不一样的,是1-Way ANOVA
| Drug1 | Drug2 | Drug3 |
|---|---|---|
| sub1,sub2,sub3 | sub4,sub5,sub6 | sub7,sub8,sub9 |
类似下面的,每组的受试样本一样的,是1-Way Repeated Measure ANOVA
| Drug1 | Drug2 | Drug3 |
|---|---|---|
| sub1,sub2,sub3 | sub1,sub2,sub3 | sub1,sub2,sub3 |
python代码click
import pingouin as pgaov = pg.anova(data=data, dv="dependent variable", between="group", detailed=False, effsize=False)
dv表示选择对比的数据,因变量;between表示分组;detailed表示是否输出详细信息;effsize表示是否输出eta2
上面是1-way anova的
aov = pg.rm_anova(data=None, dv=None, within=None, subject=None, detailed=False)
within表示不同的分组,subject表示个体
1-way ANOVA, 1-way RM ANOVA条件
- 独立观测
- 独立样本(1-way), 重复/配对样本(1-way RM)
- 正态分布
- 方差齐性(1-way),球性(1-way RM)
- 连续变量
- 组内随机采样
- 组间样本量平衡
4.3.4 两两配对比较
当通过1-way ANOVA拒绝零假设后,要想确定是哪几组之间的存在显著差异,就要使用Post Hoc多重检验(事后检验)(不使用多重t检验的原因同上)
python代码
pt = data.pairwise_tukey(dv="MoodGain", between="Grouop")其中dv是因变量,between是分组,上面是1-way的
pt = data.pairwise_ttests(dv="Scores",within="Test",subject="Sub_id",padjust="bonf")
上面是1-way RM ANOVA,不重要
最后得到的结果是
A B mean(A) mean(B) diff se T p-tukey hedges 0 anxifree joyzepam 0.7167 1.4833 -0.7667 0.1759 -4.3596 0.0015 -2.3234 1 anxifree placebo 0.7167 0.4500 0.2667 0.1759 1.5164 0.3117 0.8081 2 joyzepam placebo 1.4833 0.4500 1.0333 0.1759 5.8760 0.0010 3.1315
其中,diff=mean(A)-mean(B),se是枢轴量的standard error,T是枢轴量观测值,p-tukey是T对应的p值的修正值,hedges不管
4.3.5 2-way ANOVA
原理
| Gender\DRug | A | B |
|---|---|---|
| male | sub1,sub2,sub3 | sub4,sub5,sub6 |
| female | sub7,sub8,sub9 | sub10,sub11,sub12 |
当出现上面这种有两个变量时,使用2-way ANOVA,假设是
- H01:Factor1不同水平的均值没有差异
- H02:Factor2不同水平的均值没有差异
- H03:Factor1不同水平的均值差异与Factor2无关,即不存在交互作用
python代码
aov=data.anova(dv='MoodGain', between=["Drug","Therapy"],detailed=True)和1-way类似的,只是between中有多个变量
其报告表如下
Source SS DF MS F p-unc np2 0 Drug 3.453333 2 1.726667 31.714286 0.000016 0.840909 1 Therapy 0.467222 1 0.467222 8.581633 0.012617 0.416956 2 Drug * Therapy 0.271111 2 0.135556 2.489796 0.124602 0.293269 3 Residual 0.653333 12 0.054444 NaN NaN NaN
意义和1-way相同,但是算法不同
2-way ANOVA比两个独立的ANOVA具有更高的统计功效(statistic power),即更容易检测出主效应(很小的p值)
故即使不关心两个变量间的相互作用,也使用2-way ANOVA进行检验