Learning Bronchiole-Sensitive Airway Segmentation CNNs by Feature Recalibration and Attention Distillation
MICCAI https://doi.org/10.1007/978-3-030-59710-8_22
用注意力蒸馏机制在气管末梢加上更大的全局对齐权重
1 Introduction
本文提出的是基于CNN的模型,主要有
- 重校准模块,充分利用已经学习的特征
- 减少通道数来防止过拟合
- 防止参数减少使学习能力下降
- 这个重校准模块用的就是注意力子层
- 使用了蒸馏机制,用高分辨率的注意力图(有更多上下文)来细化低分辨率的注意力图;同时蒸馏作为辅助监督,提供了额外的监督信号
模型结构如下
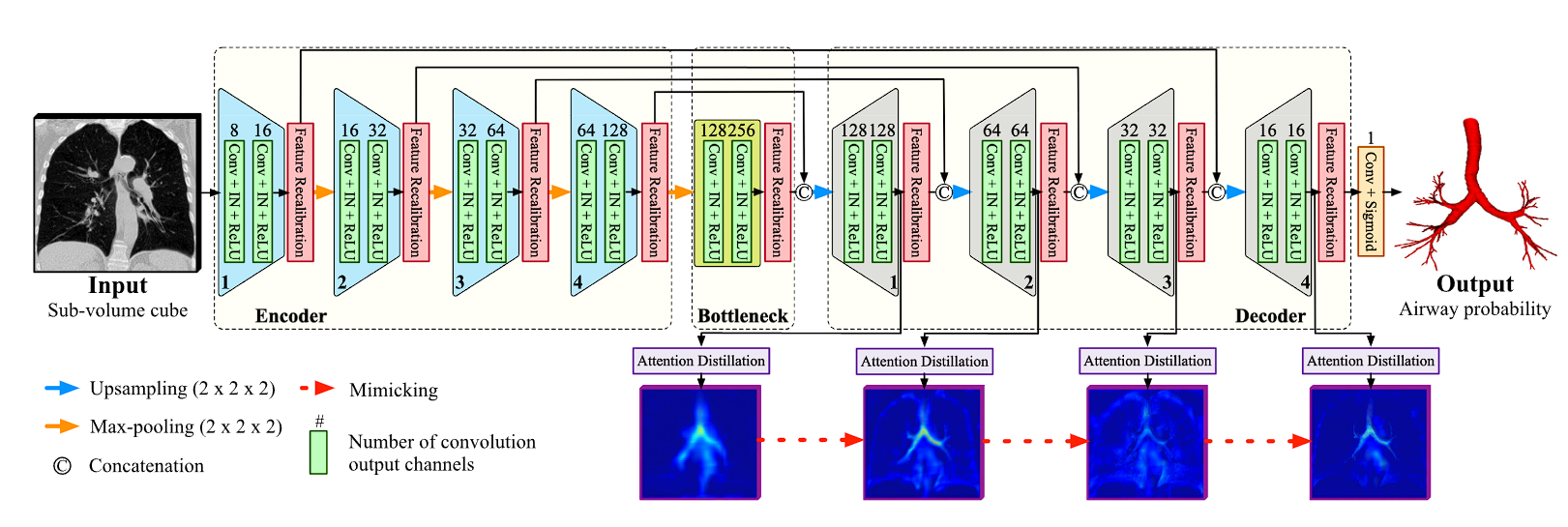
其中IN表示instance normalization
2 Method
输入的三维图像\(X\)经过模型作用后得到\(P\),\(P=\mathcal{F}(X)\),代表每个体素是气道的概率;gt值是\(Y\),一个是否为气管的Boolean掩膜
假定每一个卷积层的输出为\(A_m,m=1,...,M\),\(M\)是卷积层的个数
特征重新校准
使用一个映射\(Z(\cdot)\),生成通道描述算子\(U_m\),将其与\(A_m\)做\(A_m\odot U_m\),相当于一个权重
因为不同位置在\(A_m\)内部和\(A_i\)之间的重要性不同,简单地池化对精细/粗糙的气管特征没有区分能力
映射\(Z(\cdot)\)可以描述为
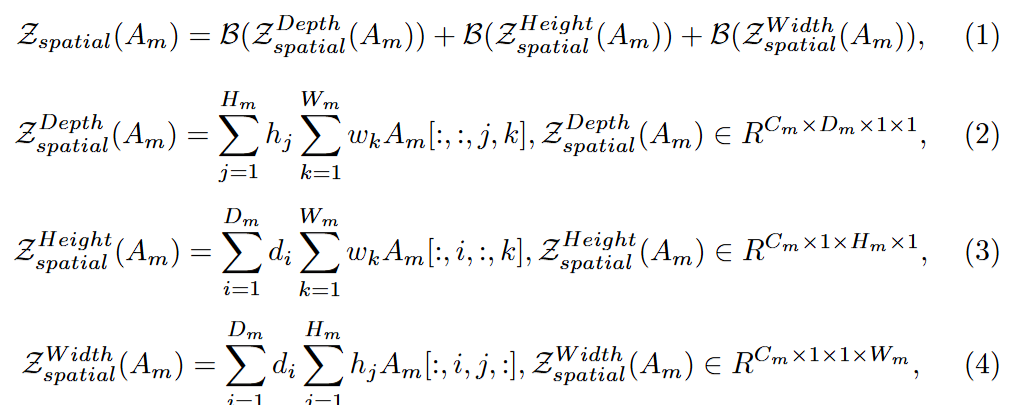
其中\(\mathcal{B}(\cdot)\)表示广播;\(h_i, d_i, w_i\)都是可以学习的权重,在训练时不同的卷积层会对重要的区域产生偏好
为了产生\(Z(A_m)\),使用下面的计算公式
\[
U_m = Z(A_m) = f_2(K_2*f_1(K_1*\mathcal{Z}_{spatial}(A_m)))
\]
其中\(K_1,K_2\)分别是1*1*1的卷积核,*表示卷积,f1是ReLU,f2是Sigmoid
使用\(K_1\)卷积后通道数被压缩为\(\frac{1}{r}\),通过调整\(K_1\)的第四维大小调整压缩比r,使用\(K_2\)卷积后通道数恢复
最终得到校准后的特征
\[
\hat{A} = A\odot U
\]
注意力蒸馏
注意力蒸馏在两个连续的卷积层之间进行,首先需要得到本层的注意力图
\[
G_m = G(A_m)
\]
其中注意力仅单通道,每个体素反应了\(A_m\)中对应体素在分割模型时的贡献,计算方法为
\[
G_m = \sum_{c=1}^{C_m}|A_m[c,:,:,:]|^p
\]
是一个没开根的L-P范数,\(p>1\),则会更关注高激活区域
这里用求和而不是最值/均值,可以减少描述整体特征的偏差(保留细节)
然后使用三线性插值\(I(\cdot)\)和空间级Softmax\(S(\cdot)\)来处理\(G_m\),得到\(\hat{G_m}=S(I(G_m))\),这一步处理是为了进行注意力蒸馏
\[
L_{\mathsf{distill}}=\sum_{m=1}^{M-1}\| \hat{G}_m-\hat{G}_{m+1} \|^2_F
\]
其中\(\| \|_F^2\)表示平方佛罗贝尼乌斯范数,相当于\(\|\|^2_2\)
蒸馏后的注意力\(G_m\)更接近\(G_{m+1}\),视觉注意力从最深层传递到最浅层,在模型拥有注意力的地方,越深层的特征是越高频的
为了保证蒸馏的方向从后向前,需要将\(\hat{G}_{m+1}\)从计算图中分离,因此,反向传播的梯度不会改变\(\hat{G}_{m+1}\)的值
模型设计
还是沿用了U-net的架构,卷积核都是3*3*3的
Encoder层没有使用注意力和蒸馏,因为特征太低维,与气道的描述无关
损失函数
结合了Dice和Focal Loss
\[
L_{seg} = -\left( \frac{2\sum_{x\in X}p(x)y(x)}{\sum_{x\in X}(p(x)+y(x))+\varepsilon} \right) - \frac{1}{|X|}\left( \sum_{x\in X}(1-p_t(x))^2\log(p_t(x)) \right)
\]
其中\(y(x)\)是体素\(x\)的真实标签,\(p(x)\)是预测值,\(p_t(x) =\begin{cases} p(x)\,\,,\,\,y(x)=1 \\ 1-p(x)\,\,,\,\,o.w.\end{cases}\)
前文还有蒸馏损失,整体损失函数为二者的线性组合
\[
L = L_{seg} + \alpha L_{distill}
\]
3 Setup
- 预处理见AirwayNet
- Adam optimizer设置参数\(\beta_1=0.5,\beta_2=0.999\),学习率设置\(2\times 10^{-4}\)
- 大图像用48的步长分块,重叠取均值,最终以0.5为阈值
- 不做后处理
- 超参数设置:\(\alpha=0.1, \varepsilon=10^{-7},p=2,r=2\)