U-Net: Convolutional Networks for Biomedical Image Segmentation
MICCAI 2015 DOI: 10.1007/978-3-319-24574-4_28
1 Introduction
CNN的典型用途是分类,但是这对于图像输入来说不够
滑动窗口CNN能够预测每个像素,通过输入中心像素的邻域;这个方式的优势是邻域作为输入,数据量比图像大很多,且可以像素级定位;缺点是训练非常慢,因为每个点都要练,而且滑动窗口的冗余很大;更大的邻域需要的池化层更多,定位的准确性和领域大小的trade-off
运用了全卷积网络的想法,用连续层来补充收缩网络,将池化层替换为上采样;为了定位特征,收缩路径的高频图像与上采样输出结合
2 Architecture
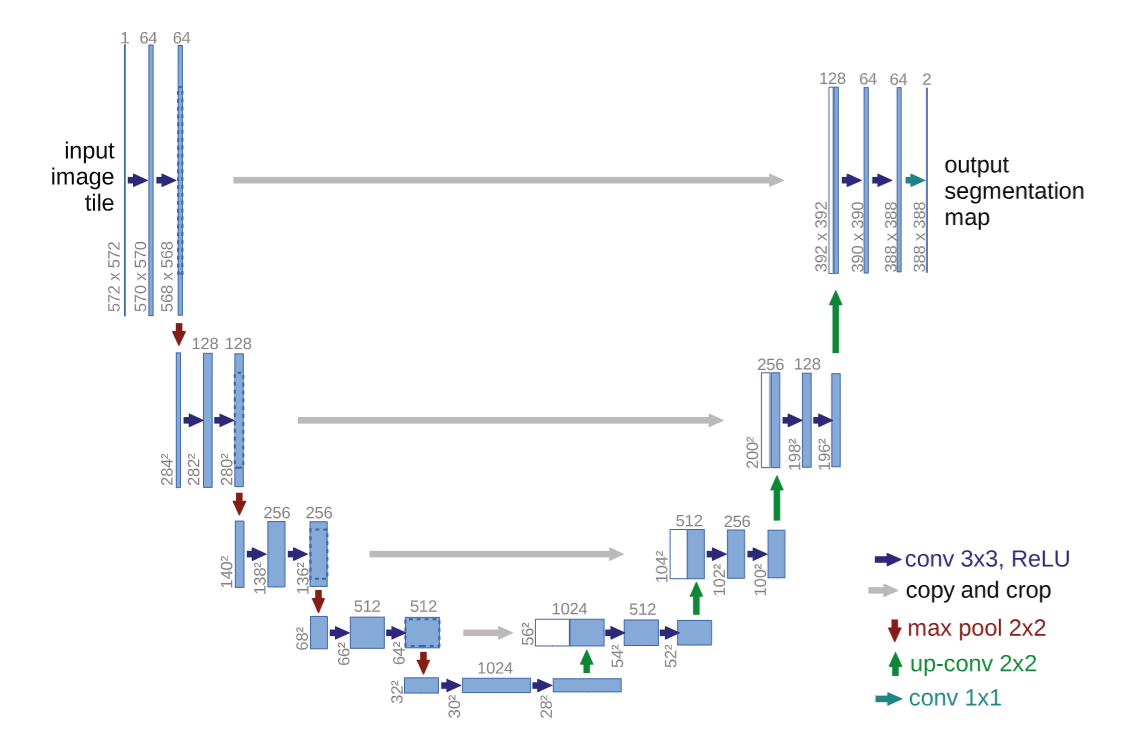
上图具体而言,输入的是一个572*572的图像
64个3*3的卷积核,得到570*570*64的特征1;向下一级输出3*3*64个输出值,计算方式为9个权重*64个通道
64个3*3*64的卷积核继续提取特征,得到特征2;为什么不是3*3做64次,因为参数太少了,而且不能整合各个通道的信息,相当于只在原来的信息上进一步卷积,而多通道则是整合各个维度信息
进行2*2邻域的最大值池化,减少特征数目,得到284*284*64的特征3
值得注意这里图像必须有偶数的高和宽
128个3*3*64的卷积核提取特征,每个得到282*282*1的特征,128个通道
以此类推,不赘述;整个模型越下方的特征的维度越高,包含的信息越低频
在右边的升支,上采样的过程中直接叠加左边的信息,可以得到更多高频信息,便于解码
最后一步使用2个1*1*64的卷积核,得到最终的分割结果
收缩路径和扩展路径的激活函数都是ReLU
使用随机梯度下降和动量下降,设置动量密度为0.99
为了充分使用GPU内存,使用大尺寸图像而不是大批量图像
在大图像的训练和分割中,需要对边缘进行镜像扩大进行推理
最后一层用了像素级别的Softmax,最大的像素输出1,其余几乎为0;最后的损失函数用了交叉熵,定义为
\[
p_k(x)=\frac{e^{a_k(x)}}{\sum_{i=1}^ke^{a_i(x)}}
\\E = \sum w(x)\lg\left(p_{l(x)}(x)\right)
\]
其中\(k\)表示被归为的类,\(l(x)\)表示Ground truth的分类,\(w\)是权重
那么很显然被分类正确的像素产生的损失绝对值小,因为\(p_{k=l(x)}(x)=1, p_{k\neq l(x)}(x)\approx0\)
网络初始化用的是He + 高斯分布